
見て試してわかる機械学習アルゴリズムの仕組み 機械学習図鑑

秋庭 伸也 著
杉山 阿聖 著
寺田 学 著
加藤 公一 監修
- 形式:
- 電子書籍
- 発売日:
- 2019年04月17日
- ISBN:
- 9784798155661
- 価格:
- 2,948円(本体2,680円+税10%)
- カテゴリ:
- 人工知能・機械学習
- キーワード:
- #プログラミング,#開発手法,#データ・データベース,#ビジネスIT
購入はこちら
機械学習アルゴリズムの違いが見てわかる!
「機械学習アルゴリズムは種類が多く、複雑で何をしているのかわかりにくい」と思ったこと、ありませんか?本書は、そのような機械学習アルゴリズムをオールカラーの図を用いて解説した機械学習の入門書です。
いままで複雑でわかりにくかった機械学習アルゴリズムを図解し、わかりやすく解説しています。アルゴリズムごとに項目を立てているので、どのアルゴリズムがどのような仕組みで動いているのか比較をしやすくしています。
これから機械学習を勉強する方だけでなく、実際に機械学習を業務で使用している方にも新しい気付きを得られるのでお勧めの1冊です。
【本書の特徴】
・複雑な機械学習アルゴリズムの仕組みを1冊で学べる
・オールカラーの図をたくさん掲載
・各アルゴリズム毎にScikit-Learnを使用したコードを記載しているので、見るだけでなく試すこともできる
・仕組みだけでなく、実際の使い方や注意点もわかる
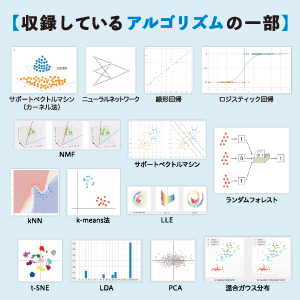
【本書で紹介するアルゴリズム】
01 線形回帰
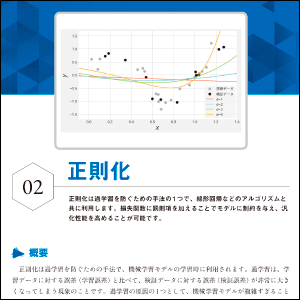
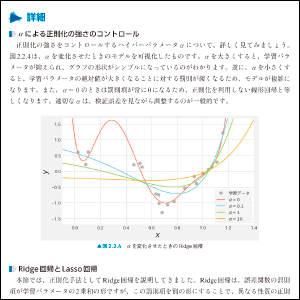
02 正則化
03 ロジスティック回帰
04 サポートベクトルマシン
05 サポートベクトルマシン(カーネル法)
06 ナイーブベイズ
07 ランダムフォレスト
08 ニューラルネットワーク
09 kNN
10 PCA
11 LSA
12 NMF
13 LDA
14 k-means
15 混合ガウス
16 LLE
17 t-SNE
※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。
※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。
※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。
※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。
(翔泳社)
複雑な機械学習アルゴリズムの仕組みを1冊で学べる!
機械学習の勉強を始めたばかりの方は、慣れない数式や統計の用語に苦労することがあるのではないでしょうか。そんなとき、1つの図が理解を助け、頭の中で機械学習のイメージができるようになることがあります。本書は、機械学習を専門としていない方々が理解しやすいように、なるべく少ない数式で図を中心に解説を行なっています。
図はすべてフルカラー!

各アルゴリズム毎にScikit-Learnを使用したコードを記載!見るだけでなく試すこともできる!
仕組みだけでなく、実際の使い方や注意点もわかる!
第1章 機械学習の基礎
1.1 機械学習の概要
1.2 機械学習に必要なステップ
第2章 教師あり学習
01 線形回帰
02 正則化
03 ロジスティック回帰
04 サポートベクトルマシン
05 サポートベクトルマシン(カーネル法)
06 ナイーブベイズ
07 ランダムフォレスト
08 ニューラルネットワーク
09 kNN
第3章 教師なし学習
10 PCA
11 LSA
12 NMF
13 LDA
14 k-means法
15 混合ガウス分布
16 LLE
17 t-SNE
第4章 評価方法および各種データの扱い
4.1 評価方法
4.2 文書データの変換処理
4.3 画像データの変換処理
第5章 環境構築
5.1 Python3 のインストール
5.2 仮想環境
5.3 パッケージインストール
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
現在表示されている正誤表の対象書籍
書籍の種類:電子書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 018 「実装方法」2つ目のサンプルコードの下にある段落 2行目 |
|
3刷 | 済 | 1刷 | 2020.02.21 | ||||||
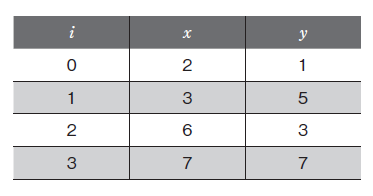
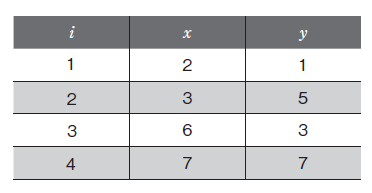
| 039 表2.1.2のi列の値 |
|
4刷 | 済 | 1刷 | 2020.02.28 | ||||||
| 043 下から8行目(数式含む) |
|
4刷 | 済 | 1刷 | 2020.02.28 | ||||||
| 053 1行目 |
|
5刷 | 済 | 1刷 | 2022.08.04 | ||||||
| 053 本文、下から5行目 |
|
5刷 | 済 | 1刷 | 2022.04.15 | ||||||
| 058 本文 上から3~6行目 |
|
4刷 | 済 | 1刷 | 2020.01.07 | ||||||
| 073 表2.6.1 「学習データ」欄1行目 |
|
3刷 | 済 | 1刷 | 2019.06.27 | ||||||
| 073 表2.6.2 左側の項目名 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 074 図2.6.2の下の本文 1行目 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 075 表2.6.3 「学習データ」欄の最下行 |
|
4刷 | 済 | 1刷 | 2020.03.25 | ||||||
| 075 表2.6.3「学習データ」欄 1行目 |
|
3刷 | 済 | 1刷 | 2019.06.27 | ||||||
| 076 表2.6.4 最下行、「砂嵐」と「探査」の数字 |
|
4刷 | 済 | 1刷 | 2020.03.25 | ||||||
| 076 表2.6.4の1行目 |
|
3刷 | 済 | 1刷 | 2020.02.21 | ||||||
| 076 表2.6.5とその下の本文 1行目 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
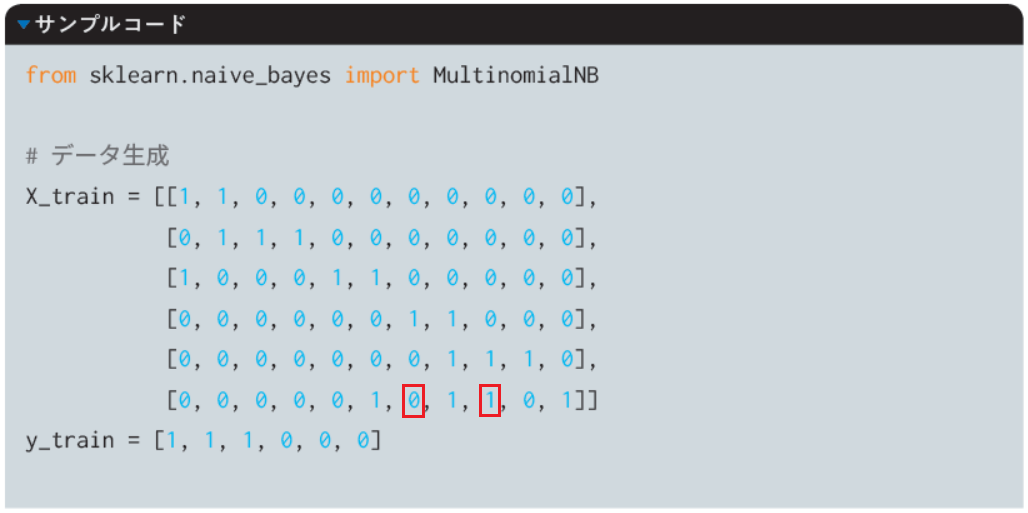
| 078 サンプルコード |
|
4刷 | 済 | 1刷 | 2022.02.25 | ||||||
| 079 コードの3行目 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 083 図2.7.3 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 089 下から1~3行目 |
|
4刷 | 済 | 1刷 | 2020.10.22 | ||||||
| 092 「詳細」上から1行目 |
|
4刷 | 済 | 1刷 | 2021.05.31 | ||||||
| 092 「サンプルコード」の続き 2行目 |
|
4刷 | 済 | 1刷 | 2021.06.23 | ||||||
| 108 1行目 |
|
5刷 | 未 | 1刷 | 2023.10.23 | ||||||
| 115 サンプルコード 下から4行目 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 140 「近傍点の数」3行目 |
|
4刷 | 済 | 1刷 | 2021.06.03 | ||||||
| 148 表4.1.1 「分類問題」の1行目 |
|
4刷 | 済 | 1刷 | 2020.04.28 | ||||||
| 176 1つ目の「サンプルコード」下から3行目 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 179 コードの最終行 |
|
2刷 | 済 | 1刷 | 2019.06.13 | ||||||
| 193 索引「M」の3行目 |
|
3刷 | 済 | 1刷 | 2020.02.21 |
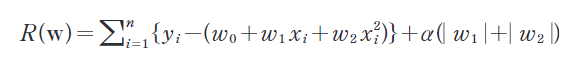








感想・レビュー 
Taizo さん
2020-04-18
ゆるふわな本かと思ってたけど、すごく幅広い範囲をカバーしてる。アルゴリズム入門だったらとりあえずこれを読んでおけばいいと思う。よくもまあこれだけの分量でこんなに分かりやすく説明できるもんだという感じ。図鑑の名に恥じずビジュアルで直感的に理解できる。pythonコードを叩きながらとりあえず試せるところもいい。環境構築から、学習の精度評価まで実用的な泥臭い部分もカバーしていて好感が持てる。
ぴよぴよ さん
2019-09-25
比較的に判りやすく、入門書としては良いのかと思いました。ですが、この本一冊だけで全てを完全に理解することはできず、一部のアルゴリズムについては、ネットで少し調べて理解したりもしました。
Kazuki さん
2020-02-29
図解もあってわかりやすいかも。それぞれの機械学習アルゴリズムに対して、その概要とアルゴリズムについて説明されている。また、はじめの機械学習に必要なステップに関してはとても役にたつと思うので繰り返し参照したい。

.png)