
現場で使える!NumPyデータ処理入門 機械学習・データサイエンスで役立つ高速処理手法

- 形式:
- 電子書籍
- 発売日:
- 2018年11月19日
- ISBN:
- 9784798155920
- 価格:
- 4,180円(本体3,800円+税10%)
- カテゴリ:
- 人工知能・機械学習
- キーワード:
- #プログラミング,#開発手法,#データ・データベース,#ビジネスIT
- シリーズ:
- AI & TECHNOLOGY
購入はこちら
機械学習・データサイエンスで役立つ高速処理手法
【本書の概要】
ビッグデータを扱う機械学習の現場では、Pythonの高機能で利用しやすい数学・科学系ライブラリが急速に広まってきています。
本書は、機械学習・データサイエンスの現場でよく利用されているNumPyの基本から始まり、
現場で使える実践的な高速データ処理手法について解説します。
特に、現場でよく扱う配列の処理に力点を置いています。
最終章では機械学習における実践的なデータ処理手法について解説します。
【NumPy(ナンパイ)とは】
NumPyは、機械学習・データサイエンスの現場で扱うことの多い多次元配列(行列やベクトル)を
処理する高水準の数学関数が充実しているライブラリです。
Python単体では遅い処理であっても、C言語なみに高速化できるケースもあり、
機械学習・データサイエンスの分野におけるデータ処理に欠かせないライブラリとなっています。
【対象読者】
機械学習エンジニア、データサイエンティスト
【著者紹介】
吉田拓真(よしだ・たくま)
データサイエンス関連のサービスを提供する株式会社Spot 代表取締役社長。
Webメディア『DeepAge』編集長。
尾原 颯(おはら・そう)
東京大学工学部機械工学科所属。
大学ではハードウェア寄りの勉強が多め。
趣味はアカペラとテニス。基本的に運動が好き。最近、ランニングを始める。
※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。
※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。
※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。
※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。
(翔泳社)
Chapter 1 NumPyの基本
1.1 NumPyの基本とインストール方法
1.2 多次元データ構造ndarrayの基礎
1.3 ブロードキャスト
1.4 スライシング
1.5 軸(axis)と次元数(ndim)について
1.6 ndarrayの属性(attribute)shape
1.7 要素のデータ型(dtype)の種類と指定方法
1.8 コピー(copy)とビュー(view)の違い
Chapter 2 NumPy配列を操作する関数を知る
2.1 配列を形状変換するreshape
2.2 配列末尾へ要素を追加するappend
2.3 配列の真偽判定に役立つallとany
2.4 条件を満たす要素のインデックスを取得するwhere
2.5 最大値、最小値を抜き出すamax、maxとamin、min
2.6 配列の最大要素のインデックスを返すargmax
2.7 配列の軸の順序を入れ替えるtranspose
2.8 ソートをするsortとargsort
2.9 配列同士を連結する、NumPyのvstackとhstackの使い方
2.10 データを可視化するmatplotlibの使い方
2.11 要素がゼロの配列を生成する関数のまとめ
2.12 要素が1の配列を生成するones
2.13 連番や等差数列を生成するarange
2.14 線形に等間隔な数列を生成するlinspace
2.15 単位行列を生成するeyeとidentity
2.16 未初期化の配列を生成するempty
2.17 randomモジュールを使った配列操作・乱数生成方法
2.18 配列を1次元に変換するflatten
2.19 loadtxtとsavetxtを使ってテキストファイルを読み書きする
2.20 配列データをそのまま読み書きするloadとsave
2.21 bufferをndarrayに高速変換するfrombuffer
2.22 非ゼロ要素を抽出するnonzero
2.23 flattenよりも高速に配列を1次元化するravel
2.24 配列をタイル状に並べるtile
2.25 新しく配列に次元を追加するnp.newaxisオブジェクト
2.26 要素の差分と足し合わせを計算するdiffとcumsum
2.27 多次元配列の結合を行うnp.c_とnp.r_オブジェクト
Chapter 3 NumPyの数学関数を使う
3.1 NumPyの数学関数・定数のまとめ
3.2 要素の平均を求めるaverageとmean
3.3 要素の中央値を計算するmedian
3.4 要素の和を求めるsum
3.5 標準偏差を計算するstd
3.6 分散を求めるvar
3.7 共分散を求めるcov
3.8 相関係数を求めるcorrcoef
3.9 配列の要素から格子列を生成するmeshgrid
3.10 内積を計算するdot
3.11 行列式を求めるlinalg.det
3.12 行列の固有値や固有ベクトルを求めるlinalg.eig
3.13 行列の階数(ランク)を求めるrank
3.14 逆行列を求めるinv
3.15 直積を求めるouter
3.16 外積を求めるcross
3.17 畳み込み積分や移動平均を求めるconvolve
Chapter 4 NumPyで機械学習を実装する
4.1 配列の正規化(normalize)、標準化をする方法
4.2 線形回帰をNumPyで実装する
4.3 NumPyでニューラルネットワークを実装する:基本編
4.4 NumPyでニューラルネットワークを実装する:理論編
4.5 NumPyでニューラルネットワークを実装する:実装編
4.6 NumPyでニューラルネットワークを実装する:多層化と誤差逆伝播法編
4.7 NumPyでニューラルネットワークを実装する:文字認識編
4.8 NumPyで強化学習を実装する
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
現在表示されている正誤表の対象書籍
書籍の種類:電子書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0-ix 上から2行目 |
|
2刷 | 済 | 1刷 | 2018.11.19 | ||||||
| 019 上から5行目と20行目(空行含む) |
|
2刷 | 済 | 1刷 | 2019.04.17 | ||||||
| 025 参照先の項番号修正 |
|
2刷 | 済 | 1刷 | 2018.11.06 | ||||||
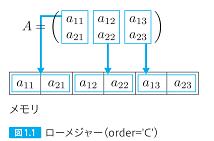
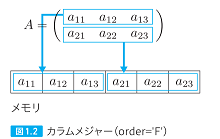
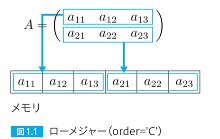
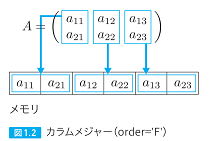
| 027,028 図1.1と図1.2の内容が逆、本文の修正 |
|
2刷 | 済 | 1刷 | 2018.11.29 | ||||||
| 071,275 ATTENTION |
|
2刷 | 済 | 1刷 | 2018.11.19 | ||||||
| 124 表2.19上の本文と表2.19のキャプション |
|
未 | 未 | 1刷 | 2020.09.04 | ||||||
| 161 表2.27(引数名:dtype、概要の内容) |
|
未 | 未 | 1刷 | 2020.09.08 | ||||||
| 168 表2.30 (引数名:stop、型の内容) |
|
未 | 未 | 1刷 | 2020.09.08 | ||||||
| 209 上から5行目 |
|
2刷 | 済 | 1刷 | 2019.05.17 | ||||||
| 210 上から6~7行目 |
|
2刷 | 済 | 1刷 | 2019.05.17 | ||||||
| 217 上から4行目、sample8→sample7 |
|
2刷 | 済 | 1刷 | 2019.05.17 | ||||||
| 241 脚注番号 |
|
2刷 | 済 | 1刷 | 2018.11.19 | ||||||
| 254 下から6行目 |
|
2刷 | 済 | 1刷 | 2019.05.17 | ||||||
| 255 6行目 MEMO内 |
|
2刷 | 済 | 1刷 | 2019.05.17 | ||||||
| 472 図4.24 左下のb2をb1に修正 |
|
2刷 | 未 | 1刷 | 2020.05.29 | ||||||
| 473 下から3行目 |
|
2刷 | 済 | 1刷 | 2020.05.29 | ||||||
| 479 MEMOの4行目 |
|
2刷 | 済 | 1刷 | 2020.05.29 | ||||||
| 481 リスト4.6の上から14行目(空行含む) |
|
2刷 | 済 | 1刷 | 2020.05.29 | ||||||
| 484 コメントの修正 |
|
2刷 | 済 | 1刷 | 2020.05.29 | ||||||
| 494 下から12行目 |
|
2刷 | 済 | 1刷 | 2020.05.29 | ||||||
| 502 コメント部分 |
|
2刷 | 済 | 1刷 | 2020.05.29 |


.png)