
Pythonによるあたらしいデータ分析の教科書




寺田 学 著
辻 真吾 著
鈴木 たかのり 著
福島 真太朗 著
- 形式:
- 書籍
- 発売日:
- 2018年09月19日
- ISBN:
- 9784798158341
- 定価:
- 2,728円(本体2,480円+税10%)
- 仕様:
- A5・328ページ
- カテゴリ:
- プログラミング・開発
- キーワード:
- #プログラミング,#開発環境,#開発手法,#Web・アプリ開発
- シリーズ:
- AI & TECHNOLOGY
データ分析エンジニアに求められる技術の基礎が最短で身に付く
ビッグデータの時代といわれ始めて数年が経過しました。
デバイスの進化により多くの情報がデジタル化され、
それらのデータを活用しようとデータ分析エンジニアに注目が集まっています。
この書籍では、データ分析において、
デファクトスタンダードになりつつあるプログラミング言語Pythonを活用し、
データ分析エンジニアになるための基礎を身に付けることができます。
書籍ではデータ分析エンジニアになるために必須となる技術を身につけていきます。
・データの入手や加工などのハンドリング
・データの可視化
・プログラミング
・基礎的な数学の知識
・機械学習の流れや実行方法
本書で学べること
・Pythonの基本的な文法
・データフォーマットについて
・データの前処理技術
・データの可視化技術
・既存アルゴリズムでの機械学習の実装
対象読者
データ分析エンジニアを目指す方
目次(抜粋)
第1章 データ分析とは
第2章 Pythonと環境
第3章 数学の基礎
第4章 ツールの基礎
第5章 応用:データ収集と加工
はじめに
謝辞
本書の対象読者と構成について
Chapter 1 データ分析エンジニアの役割
1.1 データ分析の世界
1.2 機械学習の位置づけと流れ
1.3 データ分析に使う主なパッケージ
Chapter 2 Pythonと環境
2.1 実行環境構築
2.2 Pythonの基礎
2.3 Jupyter Notebook
Chapter 3 数学の基礎
3.1 数式を読むための基礎知識
3.2 線形代数
3.3 基礎解析
3.4 確率と統計
Chapter 4 ライブラリによる分析の実践
4.1 NumPy
4.2 pandas
4.3 Matplotlib
4.4 scikit-learn
Chapter 5 応用:データ収集と加工
5.1 スクレイピング
5.2 自然言語の処理
5.3 画像データの処理
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
現在表示されている正誤表の対象書籍
書籍の種類:紙書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 065 「3.2.2 行列とその演算」の式3.39 |
|
3刷 | 済 | 1刷 | 2019.09.02 | ||||||
| 076 式3.60、および「●最頻値(mode)」の6行目 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 077 「●ばらつきの指標」下から5~6行目 |
|
4刷 | 済 | 1刷 | 2020.10.07 | ||||||
| 100 「●深いコピー〔copy〕」上から3つ目の「Out」の下の文 2行目 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 103 上から2行目 |
|
3刷 | 済 | 1刷 | 2019.09.18 | ||||||
| 103 1つ目の「Out」の下の文 |
|
3刷 | 済 | 1刷 | 2021.04.07 | ||||||
| 143 「●データ読み込み:CSVファイル」本文3行目 |
|
4刷 | 済 | 1刷 | 2020.07.03 | ||||||
| 170 一番上の「In」の1行目 |
|
6刷 | 済 | 1刷 | 2021.07.20 | ||||||
| 174 図4.1のキャプション |
|
4刷 | 済 | 1刷 | 2020.10.07 | ||||||
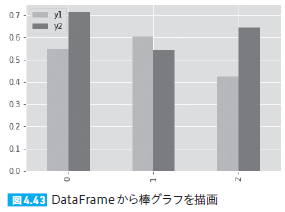
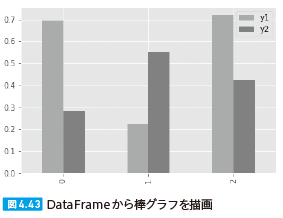
| 209 図4.43 |
|
2刷 | 済 | 1刷 | 2018.11.09 | ||||||
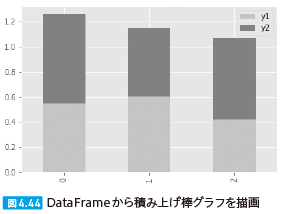
| 209 図4.44 |
|
2刷 | 済 | 1刷 | 2018.11.09 | ||||||
| 215 「欠損値の補完」のINとOUTの間 |
|
5刷 | 済 | 1刷 | 2021.05.19 | ||||||
| 219 「In」のコードと「Out」のコードの間 |
|
5刷 | 済 | 1刷 | 2021.05.21 | ||||||
| 232 Inのコード 上から5~8行目 |
|
5刷 | 済 | 1刷 | 2021.05.21 | ||||||
| 233 図4.55の下の段落3行目 |
|
6刷 | 済 | 1刷 | 2021.04.02 | ||||||
| 233 図4.54 |
|
5刷 | 済 | 1刷 | 2021.05.21 | ||||||
| 233 図4.55 |
|
5刷 | 済 | 1刷 | 2021.05.21 | ||||||
| 240 「ランダムフォレスト」2行目 |
|
未 | 済 | 1刷 | 2021.10.11 | ||||||
| 250 図4.66のキャプション |
|
2刷 | 済 | 1刷 | 2018.11.09 | ||||||
| 250 脚注※1の2行目 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 251 上から7行目 |
|
2刷 | 済 | 1刷 | 2018.11.09 | ||||||
| 255 上から6行目 |
|
6刷 | 済 | 1刷 | 2021.08.24 | ||||||
| 256 表4.6 10行目 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 268 図4.73の下の段落 2行目 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 287 「5.2.3 Bag of Words(BoW)」本ページ2つめの「In」のコード 2行目 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 288 本文、上から5行目 |
|
2刷 | 済 | 1刷 | 2018.10.09 | ||||||
| 296 箇条書きの末尾に文章追加 |
|
3刷 | 済 | 1刷 | 2020.05.26 | ||||||
| 299 本文3行目「日本語評価極性辞書」に注を追加 |
|
2刷 | 済 | 1刷 | 2018.11.09 | ||||||
| 317 INDEX 「四分位数」の読み |
|
5刷 | 済 | 1刷 | 2020.12.18 | ||||||
| 317 INDEX「最小最大正規化」と「分散正規化」のページ数 |
|
5刷 | 済 | 1刷 | 2021.05.21 | ||||||
| 317 INDEX 3列目下から5行目 |
|
2刷 | 済 | 1刷 | 2018.11.09 | ||||||
| 318 「参考文献」の上から3行目 |
|
2刷 | 済 | 1刷 | 2018.11.09 |
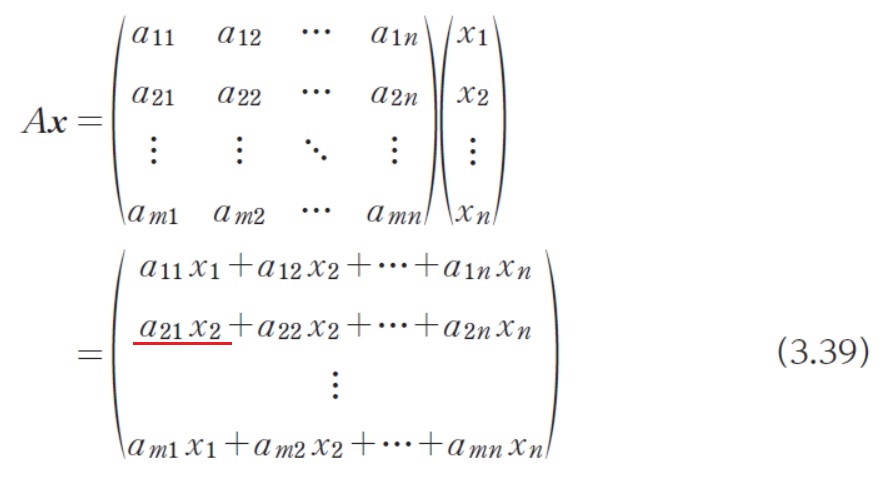








感想・レビュー 
MATSUDA, Shougo さん
2019-05-12
numpy, scipyなどライブラリによる分析、およびスクレイピングなどしっかり丁寧に説明してくれている良書。本書と本シリーズの統計学版で、一通りのpython基礎はしっかり固められそうです。
ピコピコ さん
2021-05-07
本格的なデータ分析の本を読むために必要な知識を揃える本といった印象。データ分析に必要なライブラリであるNumpy,pandas,matplotlib,scikit-learnの基礎文法と基本的な使い方がわかるようになる。私のようなデータ分析初心者には有用だったけど、もうすでにある程度データ分析の知識がある人には物足りない内容かもしれない。 紙の本を購入したのだが索引をもっと充実させてほしかった。メソッドは全部載せるくらいはしてほしい。索引が貧弱なので買うならリーダーで検索ができる電子書籍の方をお薦めする。
Kyu_zae_mon さん
2021-08-24
試験の教科書だったので読んだけど、少し簡潔すぎるか。

.png)



