
現場で使える!Python深層強化学習入門 強化学習と深層学習による探索と制御

伊藤 多一 著
今津 義充 著
須藤 広大 著
仁ノ平 将人 著
川﨑 悠介 著
酒井 裕企 著
魏 崇哲 著
- 形式:
- 電子書籍
- 発売日:
- 2019年08月07日
- ISBN:
- 9784798161433
- 価格:
- 3,740円(本体3,400円+税10%)
- カテゴリ:
- 人工知能・機械学習
- キーワード:
- #プログラミング,#開発手法,#データ・データベース,#ビジネスIT
- シリーズ:
- AI & TECHNOLOGY
購入はこちら
注目の最新AI技術!深層強化学習の開発手法がわかる!
第一線で活躍する著者陣の書下ろしによる待望の1冊!
【本書の目的】
AlphaGo(アルファ碁)でも利用されている深層強化学習。
AIサービスのみならずロボティクス分野でもその応用が期待されています。
本書は、AI開発に携わる第一線の著者陣が深層強化学習の開発手法について書き下ろした注目の1冊です。
【本書の特徴】
第1部では、まず、深層強化学習の概要について説明します。
次いで、強化学習の基礎(Q学習、方策勾配法、Actor-Critic法)と深層学習の基礎(CNN、RNN、LSTM)を解説します。
さらに、簡単な例題として倒立振子制御を取り上げ、DQNとActor-Critic法による実装例を紹介します。
第2部では、具体的な応用例として3つのアプローチを実装込みで解説します。
1つ目は、連続動作制御です。ヒューマノイドシミュレータの2足歩行制御を試みます。
2つ目は、パズル問題の解法です。巡回セールスマン問題(TSP)やルービックキューブの解探索について説明します。
3つ目は、系列データ生成です。文書生成(SeqGAN)やニューラルネットワークのアーキテクチャ探索(ENAS)を解説します。
全体を通して、行動の制御を担うエージェントのモデル化と、方策ベースの強化学習によるエージェントの学習法について学ぶことができます。
【読者が得られること】
深層強化学習による開発手法を学ぶことができます。
【対象読者】
深層強化学習を学びたい理工学生・エンジニア
※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。
※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。
※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。
※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。
(翔泳社)

本書は2部構成で深層強化学習による開発手法を学ぶことができます。

Part1では、深層強化学習の基礎となるアルゴリズムを解説し、簡単な事例(倒立振子制御)について実装例と検証結果を紹介します。

Part1で紹介されたアルゴリズムを具体的な課題に適用します。特に強化学習の数ある手法の中でも幅広い応用が期待される方策ベースの手法を取り上げ、制御を担うエージェントの実装と学習について詳しく解説します。

本書で使用するサンプルは翔泳社のサイトでダウンロードできます。
■Part 1 基礎編
CHAPTER 1 強化学習の有用性
1.1 機械学習の分類
1.2 強化学習でできること
1.3 深層強化学習とは
CHAPTER 2 強化学習のアルゴリズム
2.1 強化学習の基本概念
2.2 マルコフ決定過程とベルマン方程式
2.3 ベルマン方程式の解法
2.4 モデルフリーな制御
CHAPTER 3 深層学習による特徴抽出
3.1 深層学習
3.2 畳み込みニューラルネットワーク(CNN)
3.3 再帰型ニューラルネットワーク(RNN)
CHAPTER 4 深層強化学習の実装
4.1 深層強化学習の発展
4.2 行動価値関数のネットワーク表現
4.3 方策関数のネットワーク表現
■Part 2 応用編
CHAPTER 5 連続制御問題への応用
5.1 方策勾配法による連続制御
5.2 学習アルゴリズムと方策モデル
5.3 連続動作シミュレータ
5.4 アルゴリズムの実装
5.5 学習結果と予測制御
CHAPTER 6 組合せ最適化への応用
6.1 組合せ最適化への応用について
6.2 巡回セールスマン問題
6.3 ルービックキューブ問題
6.4 まとめ
CHAPTER 7 系列データ生成への応用
7.1 SeqGANによる文章生成
7.2 ネットワークアーキテクチャの探索
APPENDIX 開発環境の構築
AP1 ColaboratoryによるGPUの環境構築
AP2 DockerによるWindowsでの環境構築
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
-
Docker ToolBoxの利用にあたっての注意事項
Docker ToolBoxの更新にともない、ソースコードのフォルダをコンテナにマウントできなくなるバグが生じております(下記URL参照)。
https://github.com/docker/toolbox/issues/844
この状況になった場合、問題を解決するには、以下の手順にしたがってください。
手順1.書籍のAP2.2(P.287~294)にしたがい、DockerToolbox-18.09.3 をインストールしてください。
手順2.「Docker Quickstart Terminal」をダブルクリックして Docker ターミナルを起動してください[*1][*2]。
手順3.インストール先のフォルダ C:\Program Files\Docker Toolbox の下にあるイメージファイル boot2docker.iso をコピーして C:\Users\ユーザ名\.docker\machine\machines\default の下にある同名のファイルを上書き保存してください。
手順4.Dockerターミナルを終了してPCを再起動してください[*3]。
手順5.再度、Docker Quickstart Terminal をダブルクリックして Docker ターミナルを起動してください。
手順6.その後は、書籍のAP2.3およびAP2.4(P.294~301)にしたがって下さい[*4]。
[*1]: 途中でVirtual Boxの変更を問うウィンドウが何度か開きます。すべて「はい」をクリックしてください。
[*2]: しばらくしてもプロンプトが戻ってこない場合は、Enterキーを押してください。
[*3]: PCをシャットダウンする際、Virtual Boxを強制的に終了してください。
[*4]: Jupyter Notebook および Colaboratory を起動するブラウザとしては、Google Chrome または Internet Explorer を使用してください。
現在表示されている正誤表の対象書籍
書籍の種類:電子書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
カバー、表紙、大扉の著者名 |
|
2刷 | 済 | 1刷 | 2019.07.31 | ||||||
| 0-iv 「はじめに」の謝辞に記載しているお名前 |
|
3刷 | 済 | 1刷 | 2021.04.09 | ||||||
| 005 下から7行目 |
|
2刷 | 済 | 1刷 | 2019.09.11 | ||||||
| 025 式2.3、および本文の下から8行目 |
|
2刷 | 済 | 1刷 | 2019.10.09 | ||||||
| 061 上から12行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 066 上から3行目、上から10行目 |
|
2刷 | 済 | 1刷 | 2019.09.04 | ||||||
| 066 式の修正および本文の補足の追加(3か所) |
|
3刷 | 済 | 1刷 | 2022.12.21 | ||||||
| 104 上から5~8行目の下付き添え字の書体を斜体から正体にする |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 105 上から1行目 下付き添え字の"1"のみ斜体から正体にする |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 114 最下行 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 122 下から3~5行目 |
|
2刷 | 済 | 1刷 | 2019.08.29 | ||||||
| 123 上から1~2行目 |
|
2刷 | 済 | 1刷 | 2019.08.29 | ||||||
| 137 下から3行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 138 下から4行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 141 リスト4.8 上から24行目(空行含む) |
|
2刷 | 済 | 1刷 | 2019.09.04 | ||||||
| 147 下から2行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 160 下から7行目 |
|
2刷 | 済 | 1刷 | 2019.07.31 | ||||||
| 162 式5.9の最下行 第2項の係数 |
|
2刷 | 済 | 1刷 | 2020.02.18 | ||||||
| 170 図5.7のすぐ下の行 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 173 上から1行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 174,175 P.174の式5.10の第2式の右辺先頭、および、P.175 式5.11の先頭に挿入する |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 184 図5.13 |
|
2刷 | 済 | 1刷 | 2019.07.31 | ||||||
| 185 上から7行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 190 下から2行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 211 下から2行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 245 下から2行目 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 264 リスト7.8のキャプション |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
| 276 「●報酬(Reward)」の番号付き箇条書きの2、3、4 |
|
2刷 | 済 | 1刷 | 2019.10.24 | ||||||
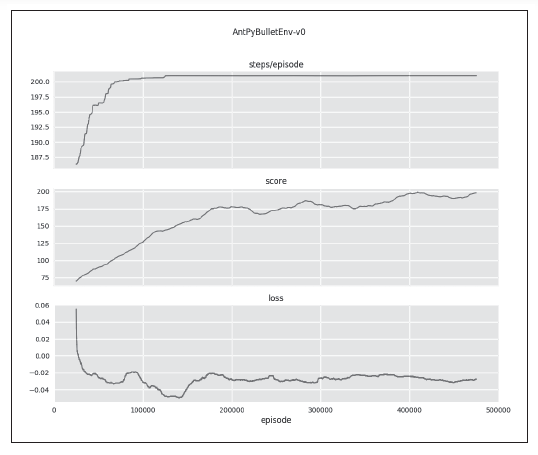
| 288 図AP.10 |
|
2刷 | 済 | 1刷 | 2022.01.04 | ||||||
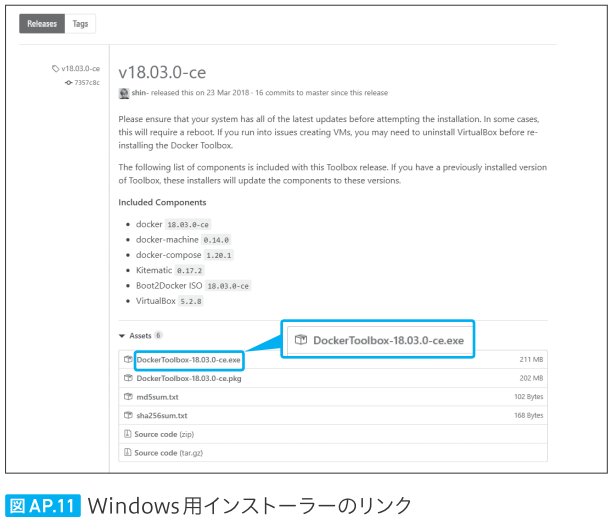
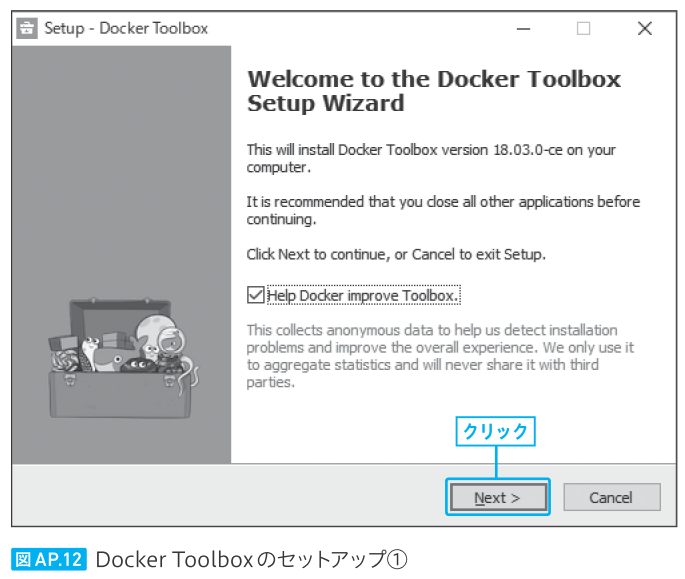
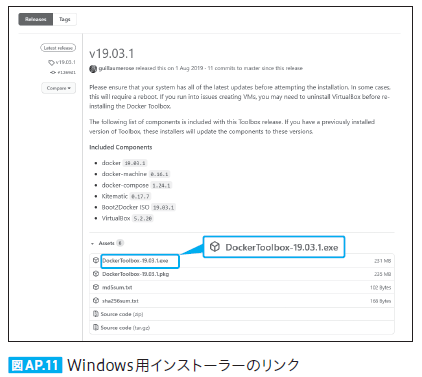
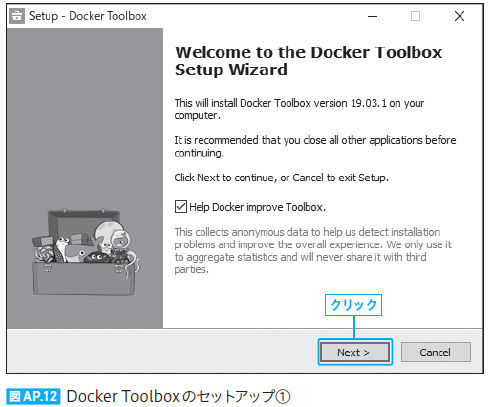
| 289 本文 上から1,2行目、図 AP.11、図 AP.12 |
|
2刷 | 済 | 1刷 | 2019.08.22 | ||||||
| 294 脚注9 |
|
2刷 | 済 | 1刷 | 2019.08.20 | ||||||
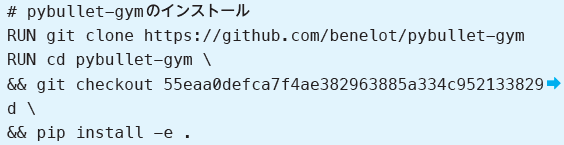
| 296 「リストAP.1」# pybullet-gymのインストール |
|
2刷 | 済 | 1刷 | 2022.01.04 | ||||||
| 298 「ATTENTION AP.1」を「COLUMN AP.1」に差し替え |
|
2刷 | 済 | 1刷 | 2022.01.05 | ||||||
| 307 参考文献 №8~13 |
|
2刷 | 済 | 1刷 | 2022.01.05 |
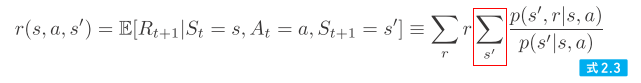 ・本文
・・・矢の先にある行動を選択する確率(方策確率)と・・・
・本文
・・・矢の先にある行動を選択する確率(方策確率)と・・・
 ・本文
・・・矢の先にある状態に遷移する確率と・・・
・本文
・・・矢の先にある状態に遷移する確率と・・・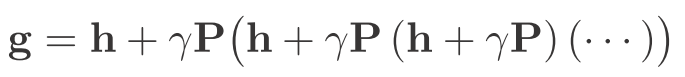
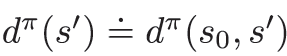
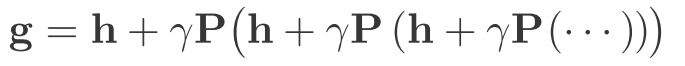
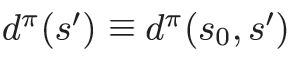


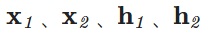
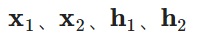
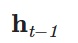
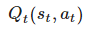 を更新します。
を更新します。
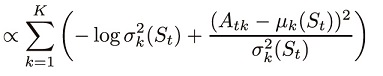

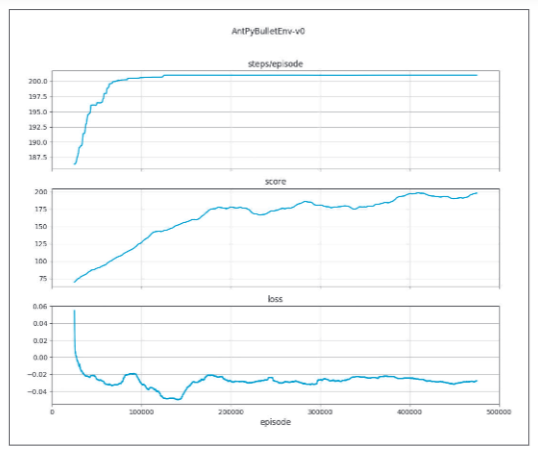


感想・レビュー 
kaida6213 さん
2021-11-06
入門と冠しているが中々難しい内容。他の本で基礎を学んでから読んでみると、非常にコンパクトに情報がまとまっていて良書だと感じた。後半半分以上最近の事例や応用事例なのも新しい知識を得られてマル。
アボカド さん
2019-11-30
第2章の理論が難解だが,コピー用紙にメモしながら理解すれば何とかなるが,それでも結構難しい。強化学習を始めて学ぶひとは,”ロボットインテリジェンス”という本をお勧めする。これはExcelVBAを使った強化学習解説本で基本のQ学習を理解できる。

.png)