達人に学ぶDB設計 徹底指南書 ~初級者で終わりたくないあなたへ




ミック 著
- 形式:
- 書籍
- 発売日:
- 2012年03月15日
- ISBN:
- 9784798124704
- 定価:
- 2,860円(本体2,600円+税10%)
- 仕様:
- A5・360ページ
- カテゴリ:
- データベース
- キーワード:
- #データ・データベース,#ネットワーク・サーバ・セキュリティ,#システム運用,#開発環境
DB設計の基礎と実践ノウハウが身につく一冊
本書は、好評を博した『達人に学ぶ SQL徹底指南書』の続編という位置づけで、プロのデータベース(DB)エンジニアである著者が、DB設計の基礎と実践ノウハウをやさしく手ほどきする指南書です。初級者が押さえておくべきDB設計の基礎知識やポイント、正規化/非正規化のケーススタディ、テーブル設計のやってはいけないバッドノウハウ、注意すべきグレーノウハウなどを丁寧に解説します。豊富なサンプルと練習問題で、現場で通用する実践的な力が身につきます。DBエンジニアを目指す人、DB設計の基礎と実践をしっかり学びたい人、脱初級を目指すアプリケーション開発者やDBエンジニアなど、DB設計・開発に携わるすべての方におすすめの一冊です。
第1章 データベースを制する者はシステムを制す
1-1 システムとデータベース
データ処理としてのシステム
データと情報
1-2 データベースあれこれ
データベースの代表的なモデル
DBMSの違いは設計に影響するか?
1-3 システム開発の工程と設計
システム開発の設計工程
設計工程と開発モデル
1-4 設計工程とデータベース
DOAとPOA
3層スキーマ
概念スキーマとデータ独立性
演習問題
第2章 論理設計と物理設計
2-1 概念スキーマと論理設計
論理設計のステップ
エンティティの抽出
エンティティの定義
正規化
ER図の作成
2-2 内部スキーマと物理設計
物理設計のステップ
テーブル定義
インデックス定義
ハードウェアのサイジング
ストレージの冗長構成
ファイルの物理配置
2-3 バックアップ設計
バックアップの基本分類
完全/差分/増分
フルバックアップ
差分バックアップ
増分バックアップ
バックアップ方式にもトレードオフがある
どんなバックアップ方式を採用すべきか?
2-4 リカバリ設計
リカバリとリストア
リストアとロールフォワード
演習問題
第3章 論理設計と正規化 ~なぜテーブルは分割する必要があるのか?
3-1 テーブルとは何か?
二次元表≠テーブル
3-2 テーブルの構成要素
行と列
キー
制約
テーブルと列の名前
3-3 正規化とは何か?
正規形の定義
3-4 第1正規形
第1正規形の定義 ~スカラ値の原則
第1正規形を作ろう
なぜ一つのセルに複数の値を入れてはダメなのか? ~関数従属性
3-5 第2正規形 ~部分関数従属
第2正規化を行う
第2正規形でないと何が悪いのか?
無損失分解と情報の保存
3-6 第3正規形 ~推移的関数従属
推移的関数従属
第3正規化を行う
3-7 ボイス-コッド正規形
3次と4次の狭間
ボイス-コッド正規化を行う
3-8 第4正規形
多値従属性 ~キーと集合の対応
第4正規化を行う
第4正規形の意義
3-9 第5正規形
第5正規化を行う
3-10 正規化についてのまとめ
正規化の三つのポイント
世紀かは常にするべきか?
演習問題
第4章 ER図 ~複数のテーブルの関係を表現する
4-1 テーブルが多すぎる!
4-2 テーブル同士の関連を見抜く
1対1、1対多、多対多
4-3 ER図の描き方
テーブル(エンティティ)の表記方法
IE表記法でER図を描く
IDEF1XでER図を描く
4-4 「多対多」と関連実体
演習問題
第5章 論理設計とパフォーマンス ~正規化の欠点と非正規化
5-1 正規化の功罪
正規化とSQL(検索)
正規化とSQL(更新)
正規化と非正規化、どちらが正解なのか?
5-2 非正規化とパフォーマンス
サマリデータの冗長性とパフォーマンス
選択条件の冗長性とパフォーマンス
5-3 冗長性とパフォーマンスのトレードオフ
更新時のパフォーマンス
データのリアルタイム性
改修コストの大きさ
演習問題
第6章 データベースとパフォーマンス
6-1 データベースのパフォーマンスを決める要因
インデックス
統計情報
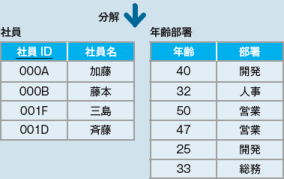
6-2 インデックス設計
まずはB-treeインデックスから
B-treeインデックスの長所
B-treeインデックスの構造
6-3 B-treeインデックスの設計方針
B-treeインデックスはどの列に作れば良いか?
B-treeインデックスとテーブルの規模
B-treeインデックスとカーディナリティ
B-treeインデックスとSQL
B-treeインデックスに関するその他の注意事項
6-4 統計情報
オプティマイザと実行計画
統計情報の設計指針
演習問題
第7章 論理設計のバッドノウハウ
7-1 論理設計の「やってはいけない」
7-2 非スカラ値(第1正規形未満)
配列型による非スカラ値
スカラ値の基準は何か?
7-3 ダブルミーニング
この列の意味は何でしょう?
テーブルの列は「変数」ではない
7-4 単一参照テーブル
多すぎるテーブルをまとめたい?
単一参照テーブルの功罪
7-5 テーブル分割
テーブル分割の種類
水平分割
垂直分割
集約
7-6 不適切なキー
キーは永遠に不変です!
同じデータを意味するキーは同じデータ型にすべし
7-7 ダブルマスタ
ダブルマスタはSQLを複雑にし、パフォーマンスを悪化させる
ダブルマスタはなぜ生じるのか
演習問題
第8章 論理設計のグレーノウハウ
8-1 違法すれすれの「ライン上」に位置する設計
8-2 代理キー ~主キーが役に立たないとき
主キーが決められない、または主キーとして不十分なケース
代理キーによる解決
自然キーによる解決
インターバル
オートナンバリングの是非
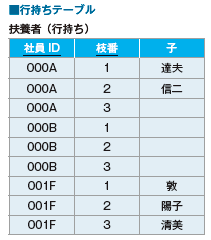
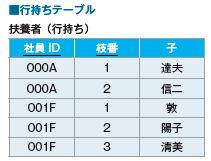
8-3 列持ちテーブル
配列型は使えない、でも配列を表現したい
列持ちテーブルの利点と欠点
行持ちテーブル
8-4 アドホックな集計キー
8-5 多段ビュー
ビューへのアクセスは「2段階」で行われる
多段ビューの危険性
8-6 データクレンジングの重要性
データクレンジングは設計に先立って行う
代表的なデータクレンジングの内容
演習問題
第9章 一歩進んだ論理設計 ~SQLで木構造を扱う
9-1 リレーショナルデータベースのアキレス腱
木構造とは?
9-2 伝統的な解法 ~隣接リストモデル
9-3 新しい解法 ~入れ子集合モデル
入れ子集合モデルを使った検索
入れ子集合モデルを使った更新
9-4 もしも無限の資源があったなら ~入れ子区間モデル
使っても使っても尽きない資源
入れ子区間モデルを使った更新
9-5 ノードをフォルダだと思え ~経路列挙モデル
ファイルシステムとしての階層
経路列挙モデルによる検索
経路列挙モデルを使った更新
9-6 各モデルのまとめ
演習問題
付録 演習問題の解答
第1章 解答
演習1-1 DBMSの情報確認
演習1-2 アプリケーション改修のタイプとコスト
第2章 解答
演習2-1 データベースサーバーのクラスタリング構成
演習2-2 ハードウェアリソースの情報取得
演習2-3 サーバーCPUの机上サイジング
第3章 解答
演習3-1 正規形の次数
演習3-2 関数従属性
演習3-3 正規化
第4章 解答
演習4-1 ER図
演習4-2 関連エンティティ
演習4-3 多対多の関連
第5章 解答
演習5-1 正規化されたテーブルに対するSQL
演習5-2 非正規化によるSQLチューニング
第6章 解答
演習6-1 ビットマップインデックスとハッシュインデックス
演習6-2 インデックスの再編成
第7章 解答
演習7-1 パーティションの特徴
演習7-2 マテリアライズドビューの機能
第8章 解答
演習8-1 ビジネスロジックの実装方法の検討
演習8-2 一時テーブル
第9章 解答
演習9-1 木構造を扱うモデルの正規形
演習9-2 実数のデータ型
索引
付属データはこちら
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
現在表示されている正誤表の対象書籍
書籍の種類:紙書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 033 6行目 |
|
17刷 | 済 | 1刷 | 2023.12.25 | ||||||
| 044 本文2行目 |
|
17刷 | 済 | 1刷 | 2023.12.25 | ||||||
| 092 4行目 |
|
2刷 | 済 | 1刷 | 2012.04.02 | ||||||
| 094 「会社」テーブル |
|
4刷 | 済 | 1刷 | 2013.07.22 | ||||||
| 099 「会社」テーブル |
|
4刷 | 済 | 1刷 | 2013.07.22 | ||||||
| 100 8~11行目 |
|
5刷 | 済 | 1刷 | 2013.11.07 | ||||||
| 101 「会社」テーブル |
|
4刷 | 済 | 1刷 | 2013.07.22 | ||||||
| 103 注釈※12の内容 |
|
5刷 | 済 | 1刷 | 2013.11.07 | ||||||
| 106 下から4~2行目 |
|
4刷 | 済 | 1刷 | 2013.09.13 | ||||||
| 107 「「社員 - チーム補佐」テーブルと「チーム補佐 - チーム」テーブルを内部結合する」上から2行目 |
|
13刷 | 済 | 1刷 | 2020.10.26 | ||||||
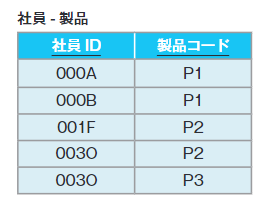
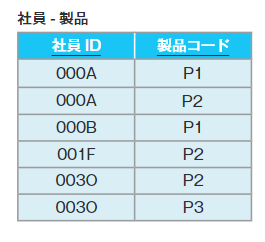
| 112 「第4正規形」の「社員-製品」 |
|
13刷 | 済 | 1刷 | 2020.10.26 | ||||||
| 120 分解後の「社員」テーブル |
|
2刷 | 済 | 1刷 | 2012.04.05 | ||||||
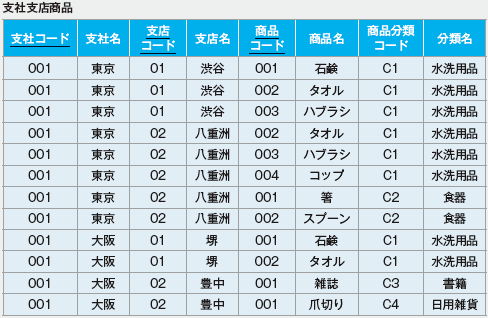
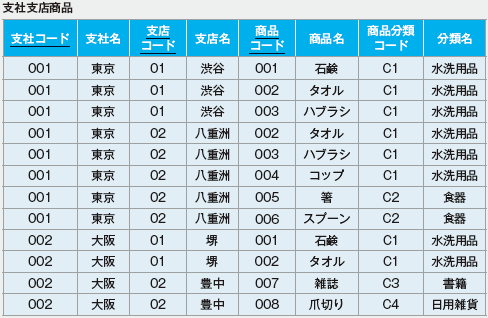
| 122 演習3-1の「支社支店商品」テーブル、7~12行目 |
|
2刷 | 済 | 1刷 | 2012.04.02 | ||||||
| 142 図5-1 「会社」テーブル |
|
4刷 | 済 | 1刷 | 2013.07.22 | ||||||
| 156 「勘どころ38」の下 本文4行目 |
|
2刷 | 済 | 1刷 | 2012.03.21 | ||||||
| 158 上から9行目 |
|
5刷 | 済 | 1刷 | 2014.03.07 | ||||||
| 178 「⑦暗黙の型変換を行なっている」の2番目のコード囲み |
|
2刷 | 済 | 1刷 | 2012.04.05 | ||||||
| 206 9行目 |
|
2刷 | 済 | 1刷 | 2012.04.02 | ||||||
| 206 「欠点3 他の代替手段がある」:下から5行目 |
|
2刷 | 済 | 1刷 | 2012.04.05 | ||||||
| 243 ページ下部、「■行待ちテーブル」 |
|
2刷 | 済 | 1刷 | 2012.03.16 | ||||||
| 244 「■行持ち⇒列持ちへの変換」リスト(ページ下部)のFROM句 |
|
2刷 | 済 | 1刷 | 2012.03.16 | ||||||
| 305 「3. 新旧サーバーの性能比を算出する」下から3行目 |
|
未 | 未 | 1刷 | 2025.07.24 | ||||||
| 307 「演習3-2 関数従属性」4行目 |
|
17刷 | 済 | 1刷 | 2023.12.25 | ||||||
| 337 6行目 |
|
16刷 | 済 | 1刷 | 2022.10.04 |

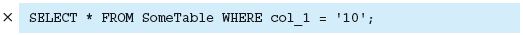

感想・レビュー 
わたなべ さん
2020-10-01
DBの設計に関して体系的に学べる。かなり基本的なことが書かれている印象。以下、個人的に参考になった箇所。①非正規化はパフォーマンス対策の最終手段(あくまで著者の意見だが)。②インデックスはカーディナリティが高くて平均的に分散しているレコードほど有効。③配列型のデータは、列持ちより行持ち。列持ちと行持ちは双方に容易に変換可能。
youkari117 さん
2019-03-18
電子書籍で読了。 本書はデータベースについて、論理設計の基本から正規化(第1~第5)、ER図、パフォーマンスとアンチパターン、そしてSQLでの木構造の取り扱いまで幅広な内容になっています。その分、それぞれの内容は必要最低限で深いというわけではありませんが、何を学ぶべきかを網羅的にカバーしている地図本として有用だと思います。 比較的読みやすいため、それほど読了まで時間はかかりません。 様々な物事にトレードオフの関係があり、それらを加味しつつ可能な限り論理設計に従うべき、という筆者の主張はよく伝わりました。
かなすぎ@起業したエンジニア さん
2020-04-18
第7章のバッドノウハウと第8章のグレーノウハウが面白くて特に勉強になった。 バッドノウハウについては、絶対しないだろうって思ってしまったので、自分が関わってる案件は苦しいところはあるものの、比較的テーブル構成がきれいで、かつ、先輩たちが自分に適切な指導をしてくれたんだなと実感して感謝の念しかない。グレーノウハウの判断は本当に難しいし、正解はないだろうな。一番最初にDB設計をする時にすべてを想定しきることはできないし、思わぬ仕様変更にも柔軟に対応するためには、グレーゾーンを責めないといけないのは納得。
関連情報

.png)