
プログラマのためのSQL 第4版 すべてを知り尽くしたいあなたに


- 形式:
- 書籍
- 発売日:
- 2013年05月23日
- ISBN:
- 9784798128023
- 定価:
- 5,060円(本体4,600円+税10%)
- 仕様:
- B5変・816ページ
- カテゴリ:
- データベース
- キーワード:
- #データ・データベース,#ネットワーク・サーバ・セキュリティ,#システム運用,#開発環境
購入はこちら
日米のDBの達人、夢の共演!SQLの第一人者であるジョー・セルコの名著『Joe Celko's SQL for Smarties Fourth Edition: Advanced SQL Programming』の日本語版です。本書は、SQLの実務経験があるエンジニアを対象として、SQLプログラミングの基礎的な考え方から、テーブル操作、グループ化、集計関数、クエリの最適化など、SQL全般について詳しく解説した「SQLプログラミングバイブル」です。基本から高度なテクニックまで、網羅的にSQLプログラミングの知識を習得できます。翻訳・監修は『達人に学ぶSQL徹底指南書』でおなじみのミック氏が担当。SQLエンジニア必携の1冊です。




第4版への序文
著者について
翻訳・監修にあたって──ミック
サンプルコードのダウンロード
第1章 データベース VS ファイルシステム
1.1 エンティティとしてのテーブル
1.2 関連としてのテーブル
1.3 行 VS レコード
1.4 列 VS フィールド
1.5 オブジェクトとしてのテーブル
第2章 トランザクションと同時実行制御
2.1 セッション
2.2 トランザクションとACID特性
2.2.1 原子性(Atomicity)
2.2.2 一貫性(Consistency)
2.2.3 独立性(Isolation)
2.2.4 耐久性(Durability)
2.3 同時実行制御
2.3.1 5つの現象
2.3.2 分離レベル
2.4 悲観的な同時実行制御
2.5 スナップショット分離と楽観的同時実行制御
2.6 論理的な同時実行制御
2.7 デッドロックとライブロック
第3章 スキーマレベルのオブジェクト
3.1 CREATE SCHEMA文
3.2 CREATE DOMAIN文
3.3 CREATE SEQUENCE文
3.4 CREATE ASSERTION文
3.4.1 スキーマレベルの制約をビューで実現する
3.4.2 制約のために主キーと表明を使う
3.5 キャラクタセットとそれに関連する諸概念
3.5.1 CREATE CHARACTER SET文
3.5.2 CREATE COLLATION文
3.5.3 CREATE TRANSLATION文
第4章 ロケータと特別な数
4.1 露出した物理的ロケータ
4.1.1 ROWIDと物理ディスクのアドレス
4.1.2 IDENTITY列
4.2 生成された識別子
4.2.1 GUID
4.2.2 UUID
4.2.3 業界標準の一意識別子
4.2.4 国防総省のUID
4.2.5 検証するための情報源
4.3 重複行について
4.4 シーケンス生成関数
4.4.1 一意な値の生成
4.4.2 欠番のある連番
4.5 事前に割り当てられる値
4.6 特別な数列
4.6.1 数列テーブル
4.6.2 素数
4.6.3 順序のランダムな数列
4.6.4 その他の数列
第5章 基底テーブルとそれに関連する要素
5.1 CREATE TABLE文
5.1.1 列制約
5.1.2 DEFAULT句
5.1.3 NOT NULL制約
5.1.4 CHECK制約
5.1.5 UNIQUE制約とPRIMARY KEY制約
5.1.6 REFERENCES句
5.2 入れ子のUNIQUE制約
5.2.1 オーバーラップするキー
5.2.2 一列の一意性と複数列の一意性
5.3 CREATE ASSERTION文
5.4 一時テーブル
5.4.1 一時テーブルの宣言
5.5 テーブルを操作する
5.5.1 DROP TABLE文
5.5.2 ALTER TABLE文
5.6 属性分割はしてはいけない
5.6.1 テーブルレベルの属性分割
5.6.2 行レベルの属性分割
5.7 DDLにおけるモデリングクラスの階層
5.8 その他のスキーマオブジェクト
5.8.1 スキーマテーブル
5.9 CREATE DOMAIN文
5.10 CREATE TRIGGER文
5.11 CREATE PROCEDURE文
第6章 手続き型プログラミング、半手続き型プログラミング、宣言型プログラミング
6.1 ソフトウェア開発の基礎
6.2 凝集度
6.3 結合度
6.4 大いなる跳躍
6.4.1 ありがちな間違い
6.4.2 一歩を踏み出せ
6.5 半手続き型への書き換え
6.5.1 データテーブル対ジェネレータコード
6.5.2 参照を計算で置き換える
6.5.3 フィボナッチ数列
6.6 述語で使うための関数
6.7 手続き VS 論理的分解
6.7.1 手続き的分解による解法
6.7.2 論理的分解による解法
第7章 手続き型の遺産
7.1 CREATE PROCEDURE文
7.2 CREATE TRIGGER文
7.3 カーソル
7.3.1 DECLARE CURSOR文
7.3.2 ORDER BY句
7.3.3 OPEN文
7.3.4 FETCH文
7.3.5 CLOSE文
7.3.6 DEALLOCATE文
7.3.7 カーソルの使い方
7.3.8 位置付けられたUPDATE文またはDELETE文
7.4 シーケンス
7.5 生成列
7.6 テーブル関数
第8章 補助テーブル
8.1 数列テーブル
8.1.1 リストの列挙
8.1.2 数列を循環数列にマッピングする
8.1.3 ループを置き換える
8.2 参照補助テーブル
8.2.1 単純な読み替えを行う補助テーブル
8.2.2 複数回の読み替えを行う補助テーブル
8.2.3 複数のパラメータを持つ補助テーブル
8.2.4 範囲補助テーブル
8.2.5 階層補助テーブル
8.2.6 単一参照テーブル
8.3 補助関数テーブル
8.3.1 補助テーブルを使った逆関数
8.3.2 補助関数テーブルを使った内挿
8.4 グローバル定数テーブル
第9章 正規化
9.1 関数従属性と多値従属性
9.2 第1正規形(1NF)
9.2.1 繰り返しグループについての注意
9.3 第2正規形(2NF)
9.4 第3正規形(3NF)
9.5 基本キー正規形(EKNF)
9.6 ボイス−コッド正規形(BCNF)
9.7 第4正規形(4NF)
9.8 第5正規形(5NF)
9.9 ドメイン−キー正規形(DKNF)
9.10 正規化を行うにあたっての実践的なヒント
9.11 キーのデータ型
9.11.1 自然キー
9.11.2 人工的なキー
9.11.3 露出した物理的ロケータ
9.12 非正規化に対する実践的なヒント
第10章 数値型
10.1 数値型
10.1.1 BIT、BYTE、BOOLEANデータ型
10.2 数値型の型変換
10.2.1 丸めと切り捨て
10.2.2 CAST関数
10.3 四則演算
10.4 算術とNULL
10.5 値からNULL、NULLから値への変換
10.5.1 NULLIF関数
10.5.2 COALESCE関数
10.6 数学関数
10.6.1 数論演算子
10.6.2 指数関数
10.6.3 小数を扱う関数
10.6.4 数値から文字への変換
10.7 IPアドレス
10.7.1 CHAR(39)形式での格納
10.7.2 バイナリ形式での格納
10.7.3 独立したSMALLINTでの格納
第11章 時間型
11.1 カレンダー標準についての注意事項
11.2 SQLの時間型
11.2.1 データベース内部での時間の表現
11.2.2 表示フォーマットの標準
11.2.3 タイムスタンプの扱い
11.2.4 時間の扱い
11.2.5 タイムゾーンとサマータイム
11.3 INTERVAL型
11.4 時間の計算
11.5 時間データモデルの性質
11.5.1 期間のモデリング
11.5.2 期間同士の関係
第12章 文字列型
12.1 SQLの文字列における問題
12.1.1 文字列の同値性に関する問題
12.1.2 文字列の順序に関する問題
12.1.3 文字列をグループ化するときの問題
12.2 標準の文字列関数
12.3 一般的なベンダー拡張
12.3.1 音声マッチング
12.4 カッター分類法
12.5 関数を入れ子にした文字列置換
第13章 NULL:SQLにおける失われたデータ
13.1 空のテーブルと失われたテーブル
13.2 列における失われた値
13.3 文脈と失われた値
13.4 NULLの比較
13.5 NULLと論理
13.5.1 サブクエリの述語におけるNULL
13.5.2 論理値述語
13.6 数学とNULL
13.7 関数とNULL
13.8 NULLとホスト言語
13.9 設計上のNULLの扱いに関するアドバイス
13.9.1 ホスト言語においてもNULLを避けるべし
13.10 NULLの複数の意味を使い分ける方法
第14章 複数列のデータ要素
14.1 距離関数
14.2 IPv4アドレスの格納方法
14.2.1 単純なVARCHAR(15)列で格納する方法
14.2.2 1つの整数列で格納する方法
14.2.3 4つのSMALLINT列を使う方法
14.3 IPv6アドレスの格納方法
14.3.1 単一のCHAR(32)列
14.4 通貨と他の単位との変換
14.5 社会保障番号
14.6 有理数
第15章 テーブルの操作
15.1 DELETE FROM文
15.1.1 DELETE FROM句
15.1.2 WHERE句
15.1.3 別のテーブルに基づいた削除
15.1.4 同一テーブルのデータを削除する
15.1.5 参照整合性制約を使わずに複数のテーブルから削除する
15.2 INSERT INTO文
15.2.1 INSERT INTO句
15.2.2 INSERTの性質
15.2.3 バルクロードとデータ抽出ツール
15.3 UPDATE文
15.3.1 UPDATE句
15.3.2 WHERE句
15.3.3 SET句
15.3.4 別のテーブルを使った更新
15.3.5 UPDATE文でCASE式を使う
15.4 ベンダー拡張が持つ欠陥について
15.5 MERGE文
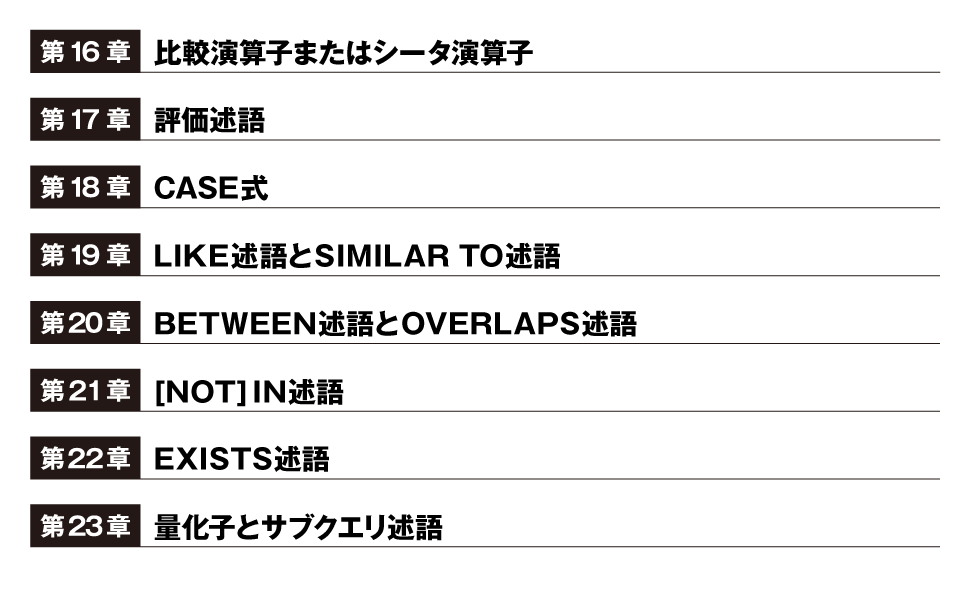
第16章 比較演算子またはシータ演算子
16.1 型変換
16.1.1 データ表示フォーマット
16.1.2 他の表示フォーマット
16.2 SQLにおける行比較
16.3 IS [NOT] DISTINCT FROM演算子
第17章 評価述語
17.1 IS NULL
17.1.1 NULLが発生する理由
17.2 IS [NOT] {TRUE | FALSE | UNKNOWN} 述語
17.3 IS [NOT] NORMALIZED述語
第18章 CASE式
18.1 CASE式
18.1.1 COALESCE関数とNULLIF関数
18.1.2 集約関数とともにCASE式を使う
18.1.3 CASE式、CHECK制約、条件法
18.2 ローゼンシュタインの特性関数
18.3 行のソート
第19章 LIKE述語とSIMILAR TO述語
19.1 文字列パターンのトリック
19.2 NULLおよび空文字列の結果
19.3 LIKEは同値性を意味するのではない
19.4 結合ではLIKE述語を避ける
19.5 CASE式とLIKEの検索条件
19.6 SIMILAR TO述語
19.7 文字列のトリック
19.7.1 文字列の中身を調べる
19.7.2 文字列の検索 VS 文字列の宣言
19.7.3 文字列にインデックスを作る
第20章 BETWEEN述語とOVERLAPS述語
20.1 BETWEEN述語
20.1.1 入力がNULLの場合の結果
20.1.2 入力が空集合の場合の結果
20.1.3 BETWEENを使ったプログラミングの小技
20.2 OVERLAPS述語
20.2.1 時間の期間とOVERLAPS述語
第21章 [NOT] IN 述語
21.1 IN述語の最適化
21.2 ORをIN述語で置き換える
21.3 NULLとIN述語
21.4 IN述語と参照整合性制約
21.5 IN述語とスカラサブクエリ
第22章 EXISTS述語
22.1 EXISTSとNULL
22.2 EXISTSと内部結合
22.3 NOT EXISTSと外部結合
22.4 EXISTSと量化子
22.5 EXISTSと参照整合性制約
22.6 EXISTSと3値論理
第23章 量化子とサブクエリ述語
23.1 スカラサブクエリの比較
23.2 量化子と失われたデータ
23.3 ALL述語と極値関数
23.4 UNIQUE述語
第24章 単純なSELECT文
24.1 SELECT文の実行順序
24.2 1レベルのSELECT文
第25章 高度なSELECT
25.1 相関サブクエリ
25.2 標準的な構文の内部結合
25.3 外部結合
25.3.1 外部結合の歴史
25.3.2 NULLと外部結合
25.3.3 自然外部結合と条件付き外部結合
25.3.4 自己外部結合
25.3.5 2つ以上の外部結合
25.3.6 外部結合と集約関数
25.3.7 完全外部結合
25.4 UNION JOIN演算子
25.5 スカラSELECT式
25.6 結合構文の新旧対決
25.7 条件付きの結合
25.7.1 在庫と注文
25.7.2 安定な結婚
25.7.3 ボールの箱詰め問題
25.8 コッドのT-結合
25.8.1 手続き型のアプローチ
第26章 仮想テーブル─ビュー、導出テーブル、共通表式、マテリアライズドクエリテーブル
26.1 クエリにおけるビュー
26.2 更新可能なビューと読み取り専用ビュー
26.3 ビューの分類
26.3.1 単一のテーブルからの射影および制限
26.3.2 計算列
26.3.3 コード化された列
26.3.4 グループ化されたビュー
26.3.5 UNIONを使ったビュー
26.3.6 結合を使ったビュー
26.3.7 入れ子のビュー
26.4 データベースエンジンにおけるビューの扱い方
26.4.1 ビューの列リスト
26.4.2 ビューの実体化
26.4.3 インライン展開
26.4.4 ポインタ構造
26.4.5 インデックスとビュー
26.5 WITH CHECK OPTION句
26.5.1 CHECK制約としてのWITH CHECK OPTION
26.6 ビューの削除
26.7 ビューと一時テーブルのどちらを使うかの判断についてのヒント
26.7.1 ビューの使い方
26.7.2 一時テーブルの使い方
26.7.3 ビューを使ったテーブルの展開
26.8 導出テーブルの使い方
26.8.1 FROM句で導出テーブルを使う
26.8.2 VALUES構築子を使った導出テーブル
26.9 共通表式
26.9.1 単純な共通表式
26.10 再帰的な共通表式
26.10.1 単純な加算
26.10.2 単純なツリー探索
26.11 マテリアライズドクエリテーブル
第27章 クエリによるデータの分割
27.1 被覆とパーティション
27.1.1 範囲による分割
27.1.2 単一列の範囲テーブル
27.1.3 関数による分割
27.1.4 数列による分割
27.1.5 ウィンドウによる分割
27.2 関係除算
27.2.1 剰余を持った除算
27.2.2 厳密な除算
27.2.3 パフォーマンスに関する注意
27.2.4 トッドの除算
27.2.5 結合を使った除算
27.2.6 集合演算を使った除算
27.3 レムレーの除算
27.4 RDBMSにおけるブール式
27.5 FIFOとLIFOの部分集合
第28章 グルーピング演算子
28.1 GROUP BY句
28.1.1 NULLとグループ
28.2 GROUP BY句とHAVING句
28.2.1 グループの特性とHAVING句
28.3 集約の階層
28.3.1 グループ化したビューによる集約の階層化
28.3.2 サブクエリによる集約の階層化
28.3.3 CASE式による集約の階層化
28.4 計算列によるグルーピング
28.5 GROUP BY句でペアを作る
28.6 GROUP BY句とソート
第29章 単純な集約関数
29.1 COUNT関数
29.1.1 DISTINCT付きの集約関数を最適化する
29.2 SUM関数
29.3 AVG関数
29.3.1 データがないグループを含む平均
29.3.2 複数列を対象にした平均
29.4 極値関数
29.4.1 簡単な極値関数
29.4.2 極値関数の一般化
29.4.3 複数の基準の極値関数
29.5 LIST関数
29.5.1 再帰共通表式とLIST関数
29.5.2 クロステーブルとLIST関数の併用
29.6 PRD関数
29.6.1 式によるPRD関数
29.6.2 対数によるPRD関数
29.7 ビット単位の集約関数
29.7.1 ビット単位のOR集約関数
29.7.2 ビット単位のAND集約関数
第30章 高度な集約、ウィンドウ関数、OLAP
30.1 スタースキーマ
30.2 GROUPING演算子
30.2.1 GROUP BY GROUPING SETS
30.2.2 ROLLUP
30.2.3 CUBE
30.2.4 SQLによるOLAPの例
30.3 ウィンドウ句
30.3.1 PARTITION BY句
30.3.2 ORDER BY句
30.3.3 ウィンドウフレーム句
30.4 ウィンドウ集約関数
30.5 順序関数
30.5.1 ROW_NUMBER
30.5.2 RANK関数とDENSE_RANK関数
30.5.3 PERCENT_RANK関数とCUME_DIST関数
30.5.4 ウィンドウ関数の使用例
30.6 ベンダー拡張
30.6.1 LEAD関数とLAG関数
30.6.2 FIRST_VALUE関数とLAST_VALUE関数
30.7 ウィンドウ関数小史
第31章 SQLにおける記述統計
31.1 最頻値
31.2 AVG関数
31.3 中央値
31.3.1 プログラミング問題としての中央値
31.3.2 特性関数を使った中央値
31.3.3 セルコの中央値
31.3.4 ウィンドウ関数を使った中央値
31.4 分散と標準偏差
31.5 平均偏差
31.6 累積統計
31.6.1 累積差分
31.6.2 累積率
31.6.3 順序関数
31.6.4 五分位と関連の指標
31.7 クロス表
31.7.1 CASE式によるクロス表
31.8 調和平均と幾何平均
31.9 SQLの記述統計における多変量
31.9.1 共分散
31.9.2 ピアソンのr
31.9.3 多変量の記述統計におけるNULL
31.10 SQL:2006における統計関数
31.10.1 分散、標準偏差、記述統計
31.10.2 相関
第32章 SQLにおける数列の扱い
32.1 大きさnのリージョンを見つける
32.2 リージョンに番号を割り振る
32.3 最も大きいリージョンを見つける
32.4 境界クエリ
32.5 ランを求めるクエリ
32.5.1 歯抜けの穴埋め
32.6 数列の歯抜け
32.7 数列の合計
32.8 リストの値を入れ替えたり、移動させる
32.9 シーケンスの始点と終点を見つける
32.10 数のリストを折り返して表示する
32.11 オーバーラップする被覆
第33章 SQLにおける配列
33.1 名前を持った列による擬似配列
33.2 添え字列を使った配列
33.3 SQLにおける行列操作
33.3.1 行列の相等性
33.3.2 行列の加法
33.3.3 行列の乗法
33.3.4 行列の転置
33.3.5 行列のソート
33.3.6 その他の行列操作
33.4 テーブルを配列に展開する
33.5 テーブル形式の配列を計算する
第34章 集合演算
34.1 UNIONとUNION ALL
34.1.1 UNIONの実行順序
34.1.2 UNIONとUNION ALLの混在
34.1.3 同じテーブルの列に対するUNION
34.2 INTERSECTとEXCEPT
34.2.1 NULLと重複行がない場合のINTERSECTとEXCEPT
34.2.2 NULLと重複行に対するINTERSECTとEXCEPT
第35章 部分集合
35.1 テーブルにおけるN番目ごとの行
35.2 テーブルからランダムな行を選択する
35.3 包含演算子
35.3.1 真部分集合演算子
35.3.2 テーブルの相等性
第36章 SQLで木と階層構造を扱う
36.1 隣接リストモデル
36.1.1 複雑な制約
36.1.2 手続き的な木の探索
36.1.3 テーブルの更新
36.2 経路列挙モデル
36.2.1 部分木とノードを見つける
36.2.2 木の深さと部分木を見つける
36.2.3 ノードと部分木の削除
36.2.4 整合性制約
36.3 入れ子集合モデル
36.3.1 座標からわかる情報
36.3.2 包含関係
36.3.3 同レベルのノード間の序列
36.3.4 階層集約
36.3.5 ノードと部分木を削除する
36.3.6 隣接リストモデルを入れ子集合モデルに変換する
36.4 木と階層構造を表現するその他のモデル
第37章 SQLにおけるグラフ
37.1 グラフを隣接リストモデルで表す
37.1.1 SQLと隣接リストモデル
37.1.2 隣接行列モデル
37.2 グラフを入れ子集合モデルで表す
37.2.1 グラフのすべてのノード
37.2.2 経路の両端
37.2.3 到達可能ノード
37.2.4 エッジ
37.2.5 入次数と出次数
37.2.6 さまざまなタイプのノードを見つける
37.2.7 非循環グラフを入れ子集合に変換する
37.3 多角形の中の点
37.4 グラフ理論の参考文献
第38章 時間を扱うクエリ
38.1 時間の計算
38.2 個人的なカレンダー
38.3 期間のシーケンス
38.3.1 期間のシーケンスにおける欠落
38.3.2 連続的な期間
38.3.3 連続的な期間における失われた時間
38.3.4 日付の引き算
38.3.5 開始日と終了日
38.3.6 開始時間と終了時間
38.4 ユリウス通日
38.5 その他の時間関数
38.6 週
38.6.1 曜日によるソート
38.7 時間データのモデリング
38.7.1 期間のペア
38.8 カレンダー補助テーブル
38.8.1 イベントと日付
38.9 2000年問題
38.9.1 ゼロ
38.9.2 閏年3
38.9.3 千年に一度
38.9.4 レガシーデータにおける奇妙な日付
38.9.5 2000年問題の影響
第39章 SQLの最適化
39.1 アクセス方法
39.1.1 シーケンシャルアクセス
39.1.2 ツリーインデックス
39.1.3 ハッシュインデックス
39.1.4 ビットベクトルインデックス
39.2 インデックス設計
39.2.1 シンプルな検索条件
39.2.2 シンプルな文字列式
39.2.3 シンプルな時間式
39.3 その他の注意事項
39.4 複数列に対するインデックスは慎重に
39.5 IN述語には要注意
39.6 UNIONを避ける
39.7 サブクエリを避けて結合を使う
39.8 SQL文の数を減らせ
39.9 ソートを避ける
39.10 クロス結合を避ける
39.11 汝、自らのオプティマイザを知れ
39.12 スキーマが変更されたら静的SQLをリコンパイルする
39.13 一時テーブルも時には役に立つ
39.14 統計情報を更新する
39.15 新機能は信用しない
参考文献
翻訳・監修を終えて──ミック
付属データはこちら
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
現在表示されている正誤表の対象書籍
書籍の種類:紙書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 076 一番下(3つ目)のコード囲み、6行目 |
|
2刷 | 済 | 1刷 | 2013.05.25 | ||||||
| 086 コード 1~9行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 093 コードの下 6行目 |
|
3刷 | 済 | 1刷 | 2015.01.14 | ||||||
| 109 1つ目のコード囲み、8行目 |
|
2刷 | 済 | 1刷 | 2013.05.25 | ||||||
| 114 コード囲み、1行目 |
|
2刷 | 済 | 1刷 | 2013.05.25 | ||||||
| 115 一番下(3つ目)のコード囲み、2行目 |
|
2刷 | 済 | 1刷 | 2013.05.25 | ||||||
| 161 1つ目のコード |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 161 1つめのコードの下 1行目 |
|
3刷 | 済 | 1刷 | 2015.10.09 | ||||||
| 175 一番下(4つ目)のコード 下から2行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 211 コード 4~6行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 213 CEIL/CEILING関数の説明 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 222 2つ目のコード囲み、10行目(3つ目のWHERE句) |
|
2刷 | 済 | 1刷 | 2013.05.25 | ||||||
| 269 2つ目のコード囲み(ド・モルガンの法則を適用した後) |
|
3刷 | 済 | 1刷 | 2015.12.22 | ||||||
| 269 1つ目のコード囲み、WHERE句 |
|
3刷 | 済 | 1刷 | 2015.03.27 | ||||||
| 310 ページ下部のコード囲み、4行目・7行目 |
|
3刷 | 済 | 1刷 | 2014.03.10 | ||||||
| 371 1行目 |
|
2刷 | 済 | 1刷 | 2013.06.24 | ||||||
| 425 コード |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 428 一番上のコード囲み、2行目と6行目 |
|
2刷 | 済 | 1刷 | 2013.05.27 | ||||||
| 437 コード |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 458 7~9 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 459 1つ目のコード囲み、3行目 |
|
4刷 | 済 | 1刷 | 2016.08.25 | ||||||
| 483 1つ目のコード 4行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 492 結果の2行上 |
|
4刷 | 済 | 1刷 | 2017.04.07 | ||||||
| 492 結果の4行目 |
|
4刷 | 済 | 1刷 | 2017.04.07 | ||||||
| 529 「Presidencies」の8行目 |
|
4刷 | 済 | 1刷 | 2017.04.07 | ||||||
| 559 2つ目のコード |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 572 表の上の本文 |
|
3刷 | 済 | 1刷 | 2015.03.27 | ||||||
| 579 3つ目の網掛け |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 579 4つ目の網掛け |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 584 本文1行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 589 3つ目のコード囲み、1行目と4行目 |
|
2刷 | 済 | 1刷 | 2013.05.27 | ||||||
| 592 下から3行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 620 2行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 685 36.2.2の1つ目のコード囲み、2行目 |
|
2刷 | 済 | 1刷 | 2013.05.27 | ||||||
| 706 37.2.7の1つ目のコード囲み、下から4行目 |
|
2刷 | 済 | 1刷 | 2013.05.27 | ||||||
| 716 「Job Apps」の下の文章 |
|
4刷 | 済 | 1刷 | 2017.02.27 | ||||||
| 754 1つ目のコード囲み 7~8行目 |
|
4刷 | 済 | 1刷 | 2017.02.27 |
感想・レビュー 
紙魚 さん
2020-07-25
理論についての良質な解説書としても、実践的で豊富な実例集としてもボリューム満載な一冊。最も眺めるだけでは理解できないサンプルコードも多かったので一読ですべてを消化するのはなかなかに難しいだろう。勉強にはなったが、カーソルを使う手続き型手法の末孫たるActiveRecordの世界に生きる人間としては、どうやって生かしていくべきか悩ましい所。
Hiroshi Obara さん
2016-08-02
ただただ面白いぞ。 全てのプログラマはRDBを利用するプロジェクトに関わっていなくても読んでみる事を進めたい。 これだけ進化しているSQLの考え方を自分のプログラムに活かさずにはいられない。開発をするときはそばに必ず置いて置くことにする。
ふらく さん
2014-09-25
読みごたえあり。実践的で理論的、日本の役に立たない理論だけのものとは違う。たた、初心者が読むには厳しいと思う。

.png)
