
Python2年生 データ分析のしくみ 体験してわかる!会話でまなべる!

森 巧尚 著
- 形式:
- 電子書籍
- 発売日:
- 2020年08月21日
- ISBN:
- 9784798164977
- 価格:
- 2,420円(本体2,200円+税10%)
- カテゴリ:
- プログラミング・開発
- キーワード:
- #プログラミング,#開発環境,#開発手法,#Web・アプリ開発
- シリーズ:
- 1年生
購入はこちら
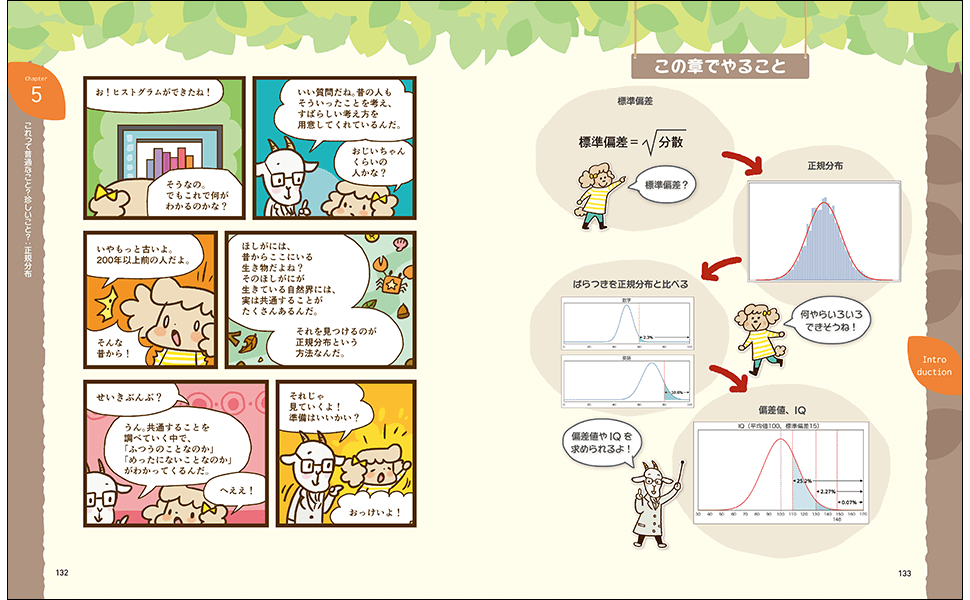
Pythonでデータ分析を体験してみよう!
【データ分析を一緒に体験しよう】
スクレイピングなどで集めた大量のデータ。
どうやって分析してたらよいか、困っていませんか?
「数式があって難しそう」
「プログラムも大変そう」
と思っている方も多いはず。
本書は、そうした方に向けて、サンプルを元にやさしく
データ分析の方法を解説しています。
【Python2年生について】
「Python2年生」は、「Python1年生」を読み終えた方を対象とした入門書です。
ある程度、技術的なことを盛り込み、本書で扱う技術について身に着けてもらいます。
『Python2年生 スクレイピングのしくみ』(ISBN:9784798161914)も刊行されています。
【対象読者】
・データの分析方法を知りたい初心者
【本書のポイント】
ヤギ博士&フタバちゃんと一緒に、データ分析の考え方から丁寧に解説。
データを分析する時に必要な前処理の方法や、データの集まりの見方、
データを見やすいグラフにする方法、データの分布の見方、予測の立て方を
解説する書籍です。
【著者プロフィール】
森 巧尚(もり・よしなお)
アプリの開発や、技術書や電子工作マガジンなどでの執筆活動。関西学院大学非常勤講師、
関西学院高等部非常勤講師、成安造形大学非常勤講師、プログラミングスクールコプリ講師など、
プログラミングに関する幅広い活動を行っている。
近著に『Python1年生』、『Python2年生 スクレイピングのしくみ』、
『Java1年生』、『動かして学ぶ!Vue.js開発入門』(いずれも翔泳社)、
『楽しく学ぶ アルゴリズムとプログラミングの図鑑』(マイナビ出版)などがある。
※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。
※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。
※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。
※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。
(翔泳社)
Pythonでデータ分析を体験してみよう!
【データ分析を一緒に体験しよう】
スクレイピングなどで集めた大量のデータ。どうやって分析してたらよいか、困っていませんか? 「数式があって難しそう」 「プログラムも大変そう」 と思っている方も多いはず。 本書は、そうした方に向けて、サンプルを元にやさしくデータ分析の方法を解説しています。
【Python2年生について】
「Python2年生」は、「Python1年生」を読み終えた方を対象とした入門書です。ある程度、技術的なことを盛り込み、本書で扱う技術について身に着けてもらいます。『Python2年生 スクレイピングのしくみ』(ISBN:9784798161914)も刊行されています。
【対象読者】
データの分析方法を知りたい初心者
【本書のポイント】
ヤギ博士&フタバちゃんと一緒に、データ分析の考え方から丁寧に解説。データを分析する時に必要な前処理の方法や、データの集まりの見方、データを見やすいグラフにする方法、データの分布の見方、予測の立て方を解説する書籍です。
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
-
よくある質問
Q:リスト6.12でエラーがでる
A:本書刊行時はpandas 1.0.1を利用していますが、それからpandas 2.2.0になり、ライブラリに仕様変更があったようです。本書で解説している「df.corr()」は、これまでは「文字列などの非数値型のデータを含む列は、自動的に除外して計算する」という便利な設定でエラーが出なかったのですが、最近のバージョンでは「文字列などの非数値型のデータを含む列は、自動的には除外されない」という仕様に変わったようです。
直前のプログラムで実行したように、「df.head()」を実行すると、以下のようにデータ内容を確認することができます。
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
species列のデータは文字列で、このためエラーが発生するようになりました。以前は、自動的にこの列を除外してくれていたのですが、これからは「A.手動で除外する」か、「B.数値以外を自動で除外する指定をする」必要があります。
Bのほうが簡単に対処できます。
df.corr()
の命令文を
df.corr(numeric_only=True)
に変更して実行してください。
-----------------------------
Q:P.161~162ページでリスト5.18や、5.19を実行すると警告がでます。
A:最新版の環境では、リスト5.18や、5.19を実行すると「FutureWarning(将来的な警告)」が出るようになりました。これはseabornに仕様変更があり「distplot」が将来的になくなるためです。しばらくは警告が出るだけで問題なく動きますが、将来的に「distplot」の表示はできなくなる可能性があります。初心者にはとても便利な命令だっただけに残念です。
(2022/09/28更新)
現在表示されている正誤表の対象書籍
書籍の種類:電子書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 033 「5.seaborn(シーボーン)をインストールします。」の本文 |
|
未 | 未 | 1刷 | 2024.01.11 | ||||||
| 037 吹き出し内 3行目 |
|
4刷 | 済 | 1刷 | 2021.08.30 | ||||||
| 047 1行目(書式のキャプション) |
|
2刷 | 済 | 1刷 | 2020.08.07 | ||||||
| 063 書式 行データを追加する(※pandas 2.0以降をお使いの場合) |
|
未 | 未 | 1刷 | 2023.10.11 | ||||||
| 063 リスト2.21(※pandas 2.0以降をお使いの場合) |
|
未 | 未 | 1刷 | 2023.10.11 | ||||||
| 076 書式:カンマ付き文字列の列データのカンマを削除する |
|
5刷 | 未 | 1刷 | 2022.07.04 | ||||||
| 083 表のAクラスの0行目の値 |
|
3刷 | 済 | 1刷 | 2021.01.07 | ||||||
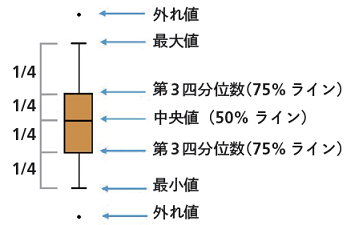
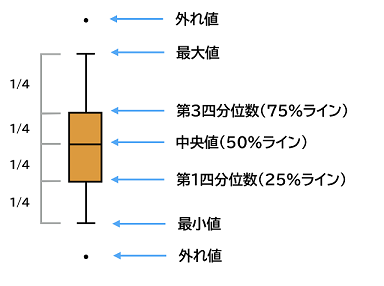
| 122 箱ひげ図の下から3つ目の第3四分位数(75%ライン)の部分は第1四分位数(25% ライン)になる |
|
2刷 | 済 | 1刷 | 2020.08.31 | ||||||
| 129 リスト4.25 上から6行目 |
|
3刷 | 済 | 2刷 | 2021.01.15 | ||||||
| 130 リスト4.26、4行目と8行目のXを小文字、5行目と9行目のYを小文字にする |
|
3刷 | 済 | 1刷 | 2020.09.04 | ||||||
| 165 本文、下から1~3行目 |
|
4刷 | 済 | 1刷 | 2021.03.24 | ||||||
| 166 リスト5.21と出力結果 |
|
4刷 | 済 | 1刷 | 2021.03.24 |
 >
>
感想・レビュー 
アルエ さん
2021-03-07
データ分析を勉強したくて読む 統計学に必要な基礎が中心 データ分析は、人間では限界がある ⇒「統計学」:「大量のデータから傾向を見つけ出して、法則を発見するための技術」
Fumie Togo さん
2021-02-14
kaggleをはじめたい私の機械学習導入本一冊目、ようやく欲しい本にたどり着いた…! 本書の内容は環境の構築~回帰曲線の目的と描写までです。必修のscikit-learnまでは本書ではフォローしていません。

.png)