
Pythonで学ぶあたらしい統計学の教科書




馬場 真哉 著
- 形式:
- 書籍
- 発売日:
- 2018年04月19日
- ISBN:
- 9784798155067
- 定価:
- 3,300円(本体3,000円+税10%)
- 仕様:
- A5・456ページ
- カテゴリ:
- 数学・統計
- キーワード:
- #理工,#データ・データベース,#理工資格,#スキルアップ
- シリーズ:
- AI & TECHNOLOGY
基礎理論を飛ばさない!
推定・検定から統計モデル・機械学習へ!
本書は統計学の理論をゼロから学べる教科書です。
IoTやビッグデータの発展によりさまざまなデータが社会にあふれ、
全てのデータを確認するのは難しくなってきています。
多くのデータから価値があるデータを作成するには統計学の知識が必須です。
【本書のポイント】
本書は統計学をはじめて勉強するかたでも、
読み進めていけるように、以下の3点を重点的に解説しています。
・データをどのように分析するのか
・なぜそのように分析するのが良いことなのか
・Pythonを使ってどのように分析するのか
【統計学を勉強するためのツールについて】
この書籍では、学習していく際のツールに、プログラミング言語のPythonを使用します。
PythonはExcelやRより自由度が高く、機械学習に多く利用されているので幅広い層から注目集めています。
Pythonに馴染むことにより、機械学習を利用したデータ分析者になるための基礎的な技術も身に付けられます。
【本書の構成】
本書は全7部構成になっています。
それぞれの部で次のようなことを解説しています。
第1部では統計学の基本を解説しています。
第2部でPythonの基本やJupyter Notebookの使い方を説明します。
第3部でPythonを用いた統計分析の方法を学びます。
第4部からは統計モデルについて学んでいきます。
第5部では正規線形モデルを解説します。
第6部それを発展させた一般化線形モデルについて解説します。
第7部は、統計学から機械学習へのつながりを学びます。
統計学やPythonのことを何も知らない方にもオススメの一冊です。
第1部 統計学の基本
第1章 統計学
第2章 標本が得られるプロセス
第3章 標本が得られるプロセスの抽象化
第4章 記述統計の基礎
第5章 母集団分布の推定
第6章 確率質量関数と確率密度関数
第7章 統計量の計算
第8章 確率論の基本
第9章 確率変数と確率分布
第2部 PythonとJupyter Notebookの基本
第1章 環境構築
第2章 Jupyter Notebookの基本
第3章 Pythonによるプログラミングの基本
第4章 numpy・pandasの基本
第3部 Pythonによるデータ分析
第1章 Pythonによる記述統計:1変量データ編
第2章 Pythonによる記述統計:多変量データ編
第3章 matplotlib・seabornによるデータの可視化
第4章 母集団からの標本抽出シミュレーション
第5章 標本の統計量の性質
第6章 正規分布とその応用
第7章 推定
第8章 統計的仮説検定
第9章 平均値の差の検定
第10章 分割表の検定
第11章 検定の結果の解釈
第4部 統計モデルの基本
第1章 統計モデル
第2章 統計モデルの作り方
第3章 データの表現とモデルの名称
第4章 パラメタ推定:尤度の最大化
第5章 パラメタ推定:損失の最小化
第6章 予測精度の評価と変数選択
第5部 正規線形モデル
第1章 連続型の説明変数を1つ持つモデル(単回帰)
第2章 分散分析
第3章 複数の説明変数を持つモデル
第6部 一般化線形モデル
第1章 さまざまな確率分布
第2章 一般化線形モデルの基本
第3章 ロジスティック回帰
第4章 一般化線形モデルの評価
第5章 ポアソン回帰
第7部 統計学と機械学習
第1章 機械学習の基本
第2章 正則化とRidge回帰・Lasso回帰
第3章 PythonによるRidge回帰・Lasso回帰
第4章 線形モデルとニューラルネットワーク
第5章 この本の次に学ぶこと
付属データはこちら
書籍の購入や、商用利用・教育利用を検討されている法人のお客様はこちら
図書館での貸し出しに関するお問い合わせはよくあるお問い合わせをご確認ください。
利用許諾に関するお問い合わせ
本書の書影(表紙画像)をご利用になりたい場合は書影許諾申請フォームから申請をお願いいたします。
書影(表紙画像)以外のご利用については、こちらからお問い合わせください。
お問い合わせ
内容についてのお問い合わせは、正誤表、追加情報をご確認後に、お送りいただくようお願いいたします。
正誤表、追加情報に掲載されていない書籍内容へのお問い合わせや
その他書籍に関するお問い合わせは、書籍のお問い合わせフォームからお送りください。
-
106ページ「%precision 3」の実行について
numpyのバージョンが上がったことにより、表示設定が変更されました。
「%precision 3」としたとき、出力がスカラー(単一の数値)ではない場合、表示される桁数が3桁になります。
出力がスカラーのときは、3桁になりません。
新しいバージョンのライブラリを使う際は注意してください。
なお、表示桁数が変わるだけで、計算の結果には影響ありません。
※上記結果は、numpyのバージョン1.16.4で確認しました。
-
107ページ「sp.sum(fish_data)」の実行について
ライブラリのバージョンが上がったことにより、scipyの一部関数の使用が非推奨(今後は使用不可となる可能性が高い)となりました。
そのため、例えば「sp.sum(fish_data)」と実行すると
「DeprecationWarning: scipy.sum is deprecated and will be removed in SciPy 2.0.0, use numpy.sum instead sp.sum(fish_data)」
などとワーニングが出力されることがあります。
ワーニングが出た場合は「sp.○○」とあるコードを「np.○○」に書き換えて実行してください。
108ページ以降も同様となります。新しいバージョンのライブラリを使う際は注意してください。
※上記結果は、numpyのバージョン1.16.4、scipyのバージョン1.4.1で確認しました。
現在表示されている正誤表の対象書籍
書籍の種類:紙書籍
書籍の刷数:全刷

書籍によっては表記が異なる場合がございます
本書に誤りまたは不十分な記述がありました。下記のとおり訂正し、お詫び申し上げます。
対象の書籍は正誤表がありません。
| ページ数 | 内容 | 書籍修正刷 | 電子書籍訂正 | 発生刷 | 登録日 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| v 余白に追加 |
|
2刷 | 済 | 1刷 | 2018.05.29 | ||||||
| 038 上から11行目 |
|
2刷 | 済 | 1刷 | 2018.04.19 | ||||||
| 057 下から3行目 |
|
2刷 | 済 | 1刷 | 2018.05.02 | ||||||
| 124 式(3-8) |
|
4刷 | 済 | 1刷 | 2020.05.27 | ||||||
| 126 式(3-10) |
|
4刷 | 済 | 1刷 | 2020.05.27 | ||||||
| 132 「3-4 実装 seaborn+pyplotによる折れ線グラフ」 の上から1行目 |
|
4刷 | 済 | 1刷 | 2020.05.27 | ||||||
| 175 上から12行目 |
|
3刷 | 済 | 1刷 | 2018.06.18 | ||||||
| 186 本文1行目 |
|
2刷 | 済 | 1刷 | 2018.04.23 | ||||||
| 193 下から2行目 |
|
2刷 | 済 | 1刷 | 2018.04.19 | ||||||
| 194 下から7行目コード中 |
|
2刷 | 済 | 1刷 | 2018.04.23 | ||||||
| 210 下から6行目 |
|
2刷 | 済 | 1刷 | 2018.04.23 | ||||||
| 210 本文下から1行目 |
|
2刷 | 済 | 1刷 | 2018.04.23 | ||||||
| 222 下から3~4行目 |
|
3刷 | 済 | 1刷 | 2018.06.18 | ||||||
| 223 上から2~3行目 |
|
4刷 | 済 | 1刷 | 2018.11.09 | ||||||
| 317 2つ目のコードの9行目 |
|
4刷 | 済 | 1刷 | 2020.05.27 |
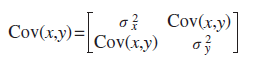
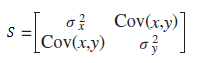
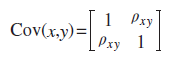
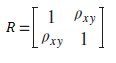
感想・レビュー 
MATSUDA, Shougo さん
2019-04-27
良書。その一言に尽きる。Python実習の面でも統計学をしっかり学べる点でもこれは習得まで何度も部分読み返しして助けてもらうこととなりそうです。
roughfractus02 さん
2018-07-23
個別的なテーマよりも書物の流れに沿ったステップアップを重視している。統計学とPythonの基礎的な説明から、数式の解説を経て、統計学のPython実装に至るラインがすっきりして感じられる構成だ。データ集計、標本分布、scipyを使用した区間推定と仮説検定を扱い、線形モデルの概要を説明する第3部、第4部があることで、statsmodelsを使った一般線形モデルの構築が辿りやすい(Seabornを使ったグラフ描画がきれいだ)。最後の第7部に機械学習と統計学の関連性の概説がある。ベイズ統計に関しての言及はない。
monotony さん
2021-10-27
統計検定の学習のお供に、毎日少しづつ写経を進めてようやく一巡。後半はほぼ素読状態・・・。次はオリジナルのデータで色々試してみたいかな。

.png)



